
Esta mañana soledada nos hemos levantado con la actualización de Screaming Frog a la versión 5.0, no cualquier update eh!
- Integración de Search Analytics de Google Search Console (mediante la api de Google Webmaster Tools). Sobran las palabras 🙂
- Auditar y analizar urls bloqueadas por robots.txt. Opción taaaaaaan útil…
- Report GA & GSC Not Matched. Páginas huérfanas en crawleos.
- Accept Language Header. Novedad sobre rastreos locales de googlebot (Post en inglés http://googlewebmastercentral.blogspot.com.es/2015/01/crawling-and-indexing-of-locale.html y soporte en español https://support.google.com/webmasters/answer/6144055)
A pesar del entusiasmo inicial y haber documentado en un tweet, todas las pruebas precoces esta misma mañana, ¡qué menos que desarrollar las novedades un poco más!
Junto con Screaming Frog, ya hay otras dos herramientas que han integrado de forma notoria y más que interesante, los datos de GA y GSC, en sus interfaces
- UrlProfiler: lo contamos en este post no hace mucho 🙂
- Sistrix: lo contaremos próximamente
Instalar la nueva versión de Screaming Frog (5.0)
Si la versión anterior de la rana ya venía con la integración de Google Analytics y otras features muy guapas (custom extractor con xpath, por ejemplo), la versión 5.0 convierte a Screaming Frog en más que completa.
Lo primero, actualizar la versión, yo cuento la versión de Mac, que es la que tengo, en Windows no cambia mucho el asunto:
- Cuando abramos la herramienta nos avisará la versión actualizada disponible para descargar

- Descargamos en el momento o cuando queramos 😀
- Cerramos Screaming Frog y ejecutamos el archivo dmg. Si no lo cerramos, no podrá reescribir la versión y nos saldrá este mensaje

- Añadimos Screaming Frog a «aplicaciones» y reemplazamos la anterior (tranquilos que nos guarda nuestra api key de la licencia de pago, si ya la teníamos introducida en versiones anteriores)


Y ya solo nos queda, ¡arrancar Screaming Frog para empezar a trastear!
Integración de Google Search Console en Screaming Frog
Una vez actualizado, ahora vamos a ver cómo podemos integrar los datos de Webmaster Tools, en nuestros crawleos y las novedades que trae la rana esta vez.
Paso 1: conectar la cuenta de Google Search Console
Nos vamos a Configuration >> Api Access >> Google Search Console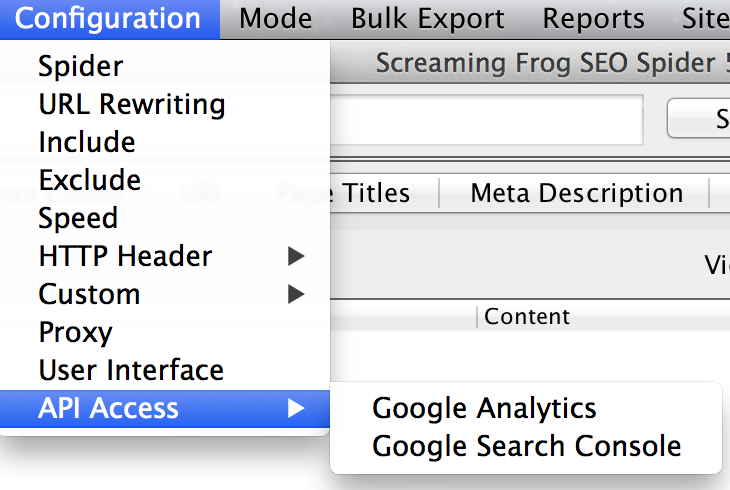
Nos abrirá un combo para vincular la cuenta que queramos, pulsando en «Connect to New Account». Antes de darle, lo ideal es que tu navegador por defecto, tengas ya iniciada sesión de google con la cuenta que quieras vincular, así es más agil todo.
Pues al pulsar, te abrirá una pestaña en el navegador para pedirte permiso de lectura (verificación OAuth 2.0).

Después de vincularlo, tenemos tres pestañas adicionales para ajustar los datos que queremos que extraiga vía API y los añada al crawleo
- Date Range. El rango de fechas que queremos analizar. Si también vais a hacer uso de Analytics, casi que hacerlos coincidir para comparar datos de los mismos periodos.

- Dimension Filter. Datos en función de dispositivo y de país.

- General. Aquí indicas si quieres que considere como iguales urls que acaban en «/» y sin «/», o la opción «case sensitive» de mayúsculas y minúsculas, esto ya depende de la necesidad que tenga cada uno.

Paso 2: configurar el crawleo.
Depende de lo que cada uno quiera hacer según el caso, no es lo mismo comprobar urls tras una migración, emular a google, comprobar datos de las urls contenidas en un sitemap, etc.
Anyway, si queremos recorrer un sitio, antes de añadir el sitio y pulsar Start, hay que ir a Configuration >> Spider y comprobar las 3 pestañas, para seleccionar aquello que cumple el comportamiento esperado en el crawleo.
- Basic: la novedad aquí es que nos deja elegir con 2 cuadros seleccionables, «Show internal/external URLs blocked by robots.txt»
- Limits: no es relevante para este post.
- Advanced: si vas a emular a googlebot, manten las opciones «respect noindex», «respect canonical», y luego selecciona desde «Configuration >> HTTP Header >> User Agent», googlebot
- Preferences: no es relevante para este post.
Por el contrario, si queremos recorrer una lista, haremos la configuración como se ha indicado anteriormente, y después habrá que modificar el modo por defecto desde «Mode >> List», y ahí, subir el listado, desde portapapeles, un archivo o a mano.
Paso 3: resultados.
Posibles lecturas
-
Datos de GSC
Podemos ver en el panel lateral, un primer resumen, y aproximación a lo que ocurre en el site analizado.
¿Qué está pasando con los contenidos que no muestran datos de GSC?
Pueden ser antiguos, no estar optimizados, y por ende, menor visibildiad, en el rango estudiado.
Yendo a los datos en sí, el panel central nos dará los datos típicos de GSC, pero sin las consultas de búsqueda.
Podemos ordenar por las columnas que queramos, peor posición media, peor CTR, etc. Tal y como haríamos en la interfaz de GSC, o extrayendo el CSV de datos para trabajarlo más a fondo.
-
Bloqueadas por robots (internal y external)
La funcionalidad de «bloqueads por robots.txt», aparecería en la pestaña Response Codes, y nos indicaría 0, o si hay páginas bloqueadas, veríamos algo parecido a esto en el panel central:
Las urls que están bloqueadas, y qué línea del robots.txt tiene la restricción que bloquea esa url para buscadores. Muy útil.
Con esto nos anticipamos a los mensajes de «Recursos Bloqueados» de GSC, y dejamos a google procesar la web al completo, con todos l
Si quieres verlo en excel, puedes descargar el report y te indicaría los inlinks también, es decir, desde donde enlaza el sitio crawleado, a los recursos bloqueados.
Descárgalo desde «Bulk Export >> Response Codes >> Blocked By Robots Inlinks».
Y así se vería en el Excel, más clarito, imposible
-
GA & GSC Not Matched
La otra funcionalidad añadida en esta versión, es reemplazar el GA Not Matched, ampliandolo a GA & GSC Not Matched. La opción es descargable desde «Reports»:
Y nos daría un archivo con las uris huérfanas, es decir, que tienen datos de GA o GSC, pero el crawleo no ha conseguido llegar a ellas, bien porque son antiguas, se han quedado pendientes de redirigir en migraciones, o el enlazado interno no les está haciendo ningún bien 🙂
Conclusiones
Quizás lo interesante de estas funcionalidades, es combinarlas con lo que ya tenía Screaming Frog, para seguir buscando contextos y centralizando datos en un mismo lugar, para detectar problemas u oportunidades, según se mire 🙂
Dado que podemos mover las columnas a nuestro antojo, combinando el crawleo con GA también, podemos tener en una misma vista, elementos SEO bastante relevantes para ver qué podemos mejorar.
- URL
- Status Code
- Titulo
- Visitas en el rango elegido
- CTR en el rango elegido
- Posición media en el rango elegido
- Tiempo de respuesta
- Palabras del contenido
- Enlaces internos que recibe
- Canonical Link
- Meta Robots
¿Tenemos urls con poco contenido?
¿Urls menos estratégicas demasiado enlazadas internamente?
¿Contenidos potentes con CTRs bajos?
¿Urls que tardan la vida en cargar?
¿Lapsus en canonicals?
…
Y con esto, a esperar las nuevas funcionalidades del siguiente update, que seguro son tan entretenidas como esta versión 5.0, ¡larga vida a la rana!
Otros contenidos interesantes sobre Screaming Frog:
Cómo visualizar el rastreo de Screaming Frog y la arquitectura del sitio webScreaming Frog Data Studio



La verdad es que es un buen juguete para pasarte un buen rato exportando los datos a csv y trabajandolos en excel o spreadsheet se puede sacar petroleo cruzando esos datos, yo lo primero que he hecho en un proyecto es ver cuales son las páginas muertas que saca el GA&GSC y republicarlas automáticamente a X cantidad de páginas por días para levantarlas de nuevo en las SERPs.
Gracias por el post MJ 🙂
¿Republicarlas?