
El inspector de urls es una nueva funcionalidad que Google ha añadido a la beta de Google Search Console, que va a dar mucho que hablar.
En el post de hoy te contamos cómo usar la herramienta de inspección de urls y por qué tienes que empezar a usarla ya mismo, pues da información de gran valor para entender las señales que estamos enviando a Google con cada url.
Qué es el Inspector de Urls
La herramienta de inspección de URLs nos ofrece información sobre qué versión de una página concreta ha indexado Google, de este modo, el inspector de urls nos dejará consultar si existen errores de AMP, de datos estructurados o si arrastramosproblemas de indexación.
Dado que está integrada en Google Search Console, en la versión Beta, solo podrás analizar urls de las propiedades que controles en GSC, y además de ver las versiones AMP y no AMP, también podrás revisar las versiones alternativas como hreflang o variantes canónicas
Cosas importantes a entender sobre el inspector de urls:
- La información que proporciona el inspector sobre cada url, es la última versión indexada que tiene Google, que la obtendrá de la fecha del «Último rastreo» (correcto) que figura en el informe «Cobertura del índice»
- Puede pasar que dicha url haya cambiado o ya no está disponible, eso se podrá ver con la opción habitual, que es «Explorar como Google»
- Cuando el inspector diga «La URL está en Google», no es 100% sinónimo de que esté en los resultados de búsqueda, además, este inspector de urls no tiene en cuenta
- Acciones manuales
- Urls bloqueadas temporalmente («Eliminar Urls» de Google Search Console)
Dónde está el Inspector de Urls
Cuando entramos a una propiedad en la que tengamos permisos, dentro de Google Search Console, tenemos que ir a la versión Beta.

Es fácil porque Google ha hecho convivir la versión de siempre con la nueva Beta, para que nos vayamos acostumbrando al nuevo diseño y funcionalidades.
Una vez dentro, tenemos una sección que se llama Inspección de la URL

Una vez ahí, nos pedirá que indiquemos una url para analizar, así de sencillo 🙂
Cómo usar el Inspector de Urls
Vamos a la chicha, ¿cómo podemos usar la herramienta de inspección de URLs?
Pues si hemos añadido una url, en el paso anterior, veremos el diagnóstico de esa url, nos indicará si está indexada o no, además de posibles mejoras a aplicar.
Vamos a ver varios ejemplos:
- Los 9 primeros ejemplos son casuísticas concretas respecto a urls
- El último ejemplo muestra como detectar urls a inspeccionar desde Cobertura del Índice
Ejemplo 1: Cuando una url es rastreable e indexable
En este primer ejemplo, vemos las características generales y útiles a tener en cuenta
- Inspección de la URL: resumen de los datos

- Ver fuente: nos va a enseñar el código fuente de la página inspeccionada
- Más información: link que va a la ayuda de Google para que podamos consultar más información
- Cobertura del índice: de primeras nos da el diagnóstico, en este caso, «Enviada e Indexada», si desplegamos, veremos más detalle
- Detección – Sitemaps: nos indica en qué sitemaps está incluida la url analizada
- Página de referencia: aquí aparecede la posible vía por lo que Google ha llegado a la url analizada, es decir, en ese post habrá un enlace directo a la url que hemos analizado. Otras causas pueden ser la jerarquía o niveles de navegación, e incluso, otras causas.
- Último rastreo: la fecha del último rastreo a esa url.
- ¿Se permite el rastreo? Si se permite el rastreo o lo que es lo mismo, si no hay instrucción en robots.txt que impida a Google acceder a rastrear el contenido de la url
- Obtención de la página: esto simplemente hace referencia a que siendo la url rastreable, también es accesible, es decir, el servidor muestra el contenido. Si se impide rastreo, aquí siempre saldrá un error, si no se impide, pueden salir errores 500 o fallos de DNS, por ejemplo, que impiden obtener la url.
- ¿Se permite la indexación? Esto se refiere a si estamos indicando expresamente que queremos impedir la indexación, por ejemplo con un «noindex». Podemos tener discrepancias en casos como bloqueos de robots.txt, que aparecerá igualmente que Si se puede indexar, ya que Google no puede acceder y ver que no se quiere indexar.
- Declarada por el usuario como canónica: aquí aparecerá la url que nosotros hemos indicado como canónica, con las distintas señales disponibles: rel canonical por etiqueta o cabeceras http, selección de dominio preferido, uso de sitemaps y redirección 301
- Seleccionada por Google como canónica: Google pondrá la que considera más relevante como canónica, cuando encuentres una url que no esperas aquí, tocará revisar si están enviándose todas las señales apropiadas para la canonización de cada url

- Mejoras: sugerencias para mejorar, en este caso, no hay nada
Ejemplo 2: Cuando una url no es rastreable
En este caso, la url no está indexada y además no le dejamos rastrear el contenido, nos indica que encuentra la url en sitemaps y que ha llegado por la jerarquía superior, es decir, la carpeta que contiene el contenido final (https://www.mjcachon.com/pruebas/url-test-3.html)
Se puede observar el error que comentábamos antes, al estar bloqueada en robots.txt, si hubiera instrucciones que la permiten indexar, Google no lo vería. No obstante, esto no significa que el robots.txt disuada de indexar, pero sin duda en ciertas casuísticas, puede ser una traba.
Es interesante esta url de ejemplo, pues no tiene etiqueta Canonical, y como se puede ver, indica N/D, pues no estamos dándole señales explícitas de canonización.

Ejemplo 3: Cuando una url no es indexable, por una etiqueta noindex
Aquí no hay mucha historia que contar, detecta el noindex y no tiene capacidad de posicionar esa url.
Esta url tampoco tiene canonical, por lo que las señales de url canónica, indican lo que indican 😀
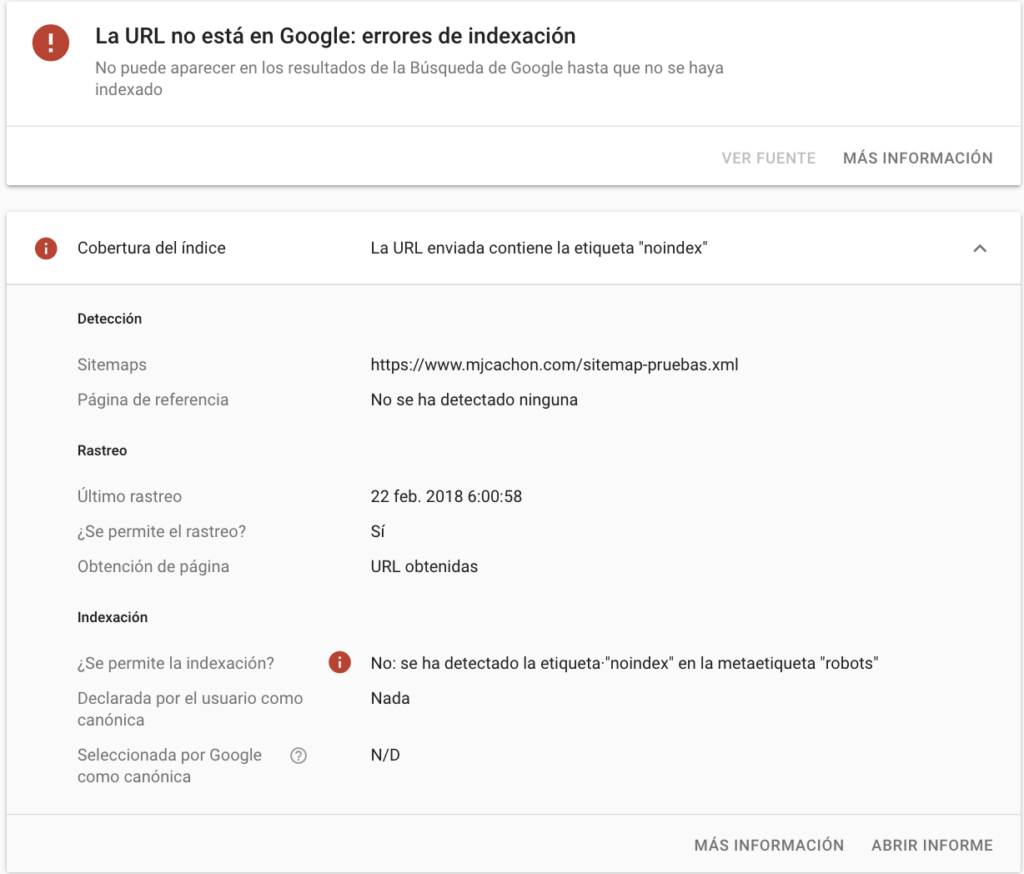
Ejemplo 4: Cuando una url tiene un canonical hacia otra
Nos indica que no se va a indexar, he usado una url de ejemplo con parámetros utml, es decir, compartida por Twitter con seguimientos de tráfico.
La url con parámetros no está en el sitemap y mola ver que Google la ha descubierto por un link acortado, se ve como la canónica coincide la que indica Google con la indicada por mi, y además, permite Inspeccionar justo la url sin parámetros.
Muy útil, y en caso que pulsemos en Abrir Informe, aterrizaremos en el informe de Cobertura del Índice de la misma casuística de esa url, Página alternativa con etiqueta canónica adecuada
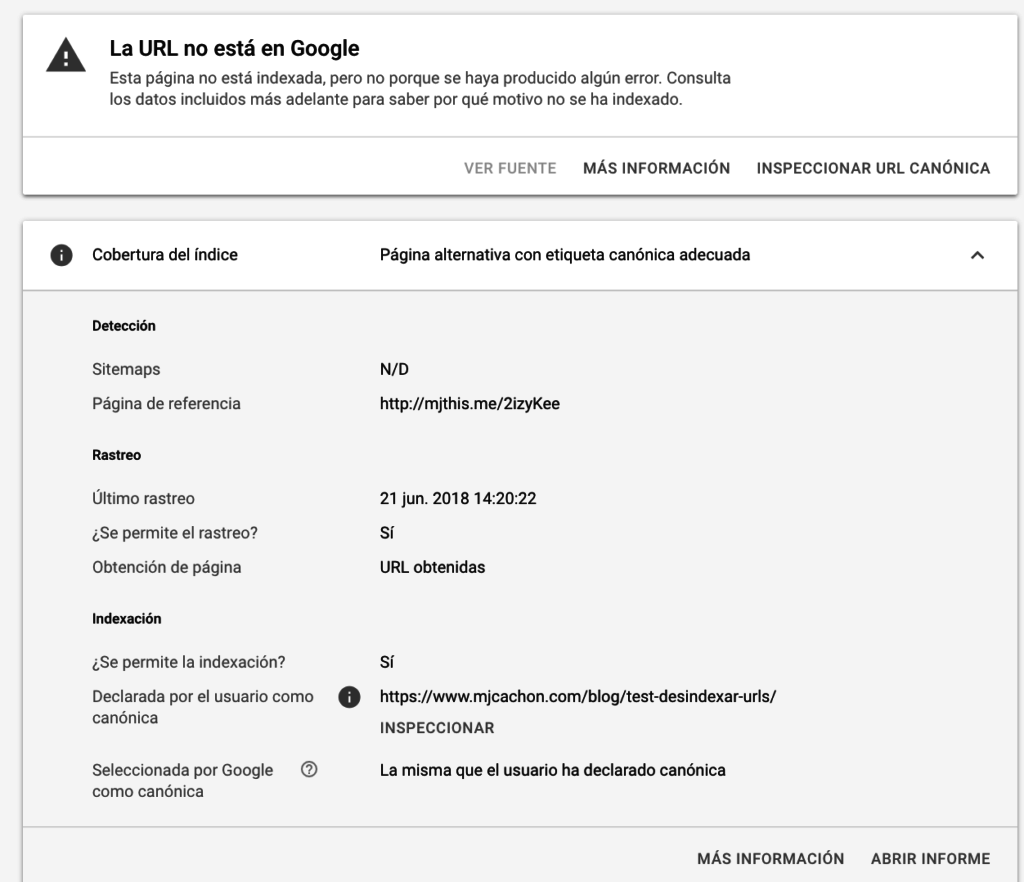
Quizás podríamos añadir una más: cuando el canonical apunta a un redirect o a un error 404….
Ejemplo 5: Cuando una url responde soft 404
Caso interesante, cuando existen urls con poco contenido, con aspecto de resultados de búsqueda vacíos (típico listado), o incluso, redirecciones no del todo relevantes e incluso masivas….
Google piensa en estos casos que la url debería responder 404 sin embargo, responde 200 OK.
Como veis en el inspector, en estos casos nos genera problemas de indexación, efectivamente haciendo el comando site: o comando info:, la url no está.
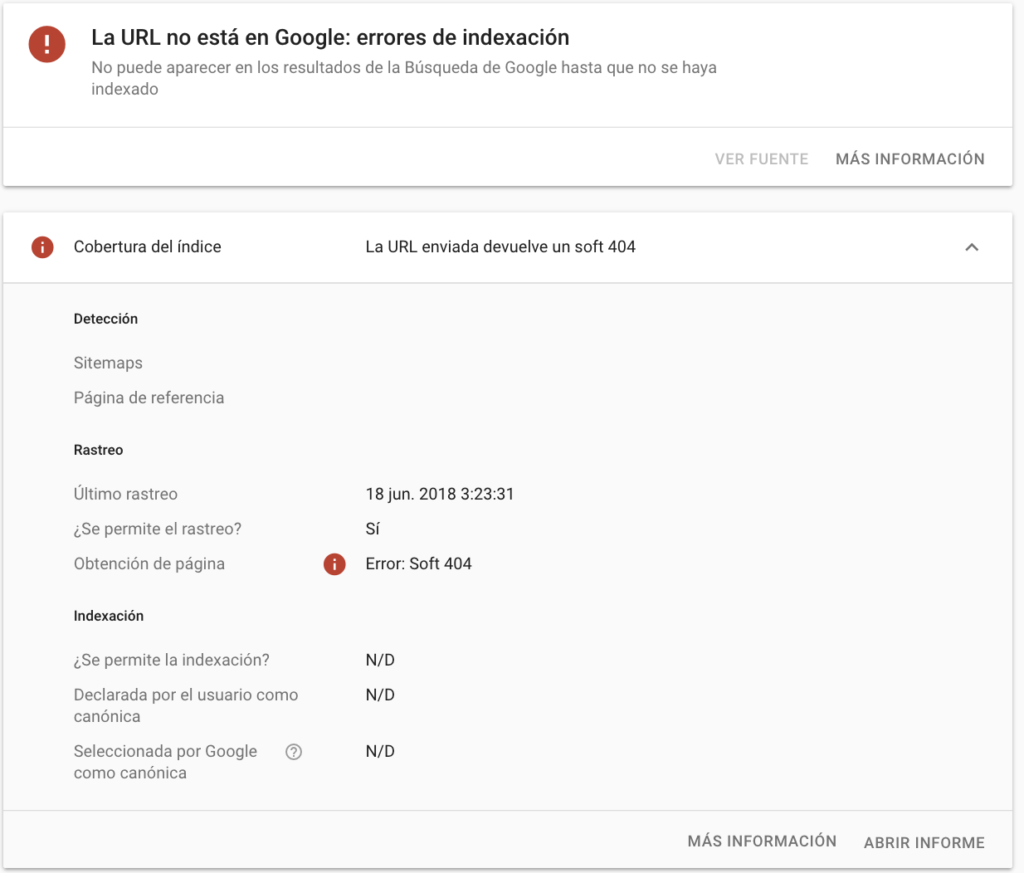
Más info de Soft 404: https://support.google.com/webmasters/answer/181708?hl=es
Ejemplo 6: Cuando una url responde error
En este caso, al ofrecer un código de error, la url no puede ser accedida, porque no se encuentra su contenido, por lo que el inspector indica un warning en «Obtención de Página».
Interesante comprobar como la url tiene un último rastreo muy reciente. Esto ya lo comentamos en el experimento de desinexación que hicimos en septiembre.

Ejemplo 7: Cuando una url redirige a una url 200 OK
Cuando hacemos una redirección, ya estamos enviando señales de la url de origen a la url de destino.
En este caso, analizamos la de origen, que ya «deja de existir», porque «existe en otra url», nos indica que no está indexada y que la canónica es la versión de la url acabada en «/».
Si inspeccionamos la de destino, figura como indexada y enviada, con métricas normales, iguales a las del ejemplo 1.
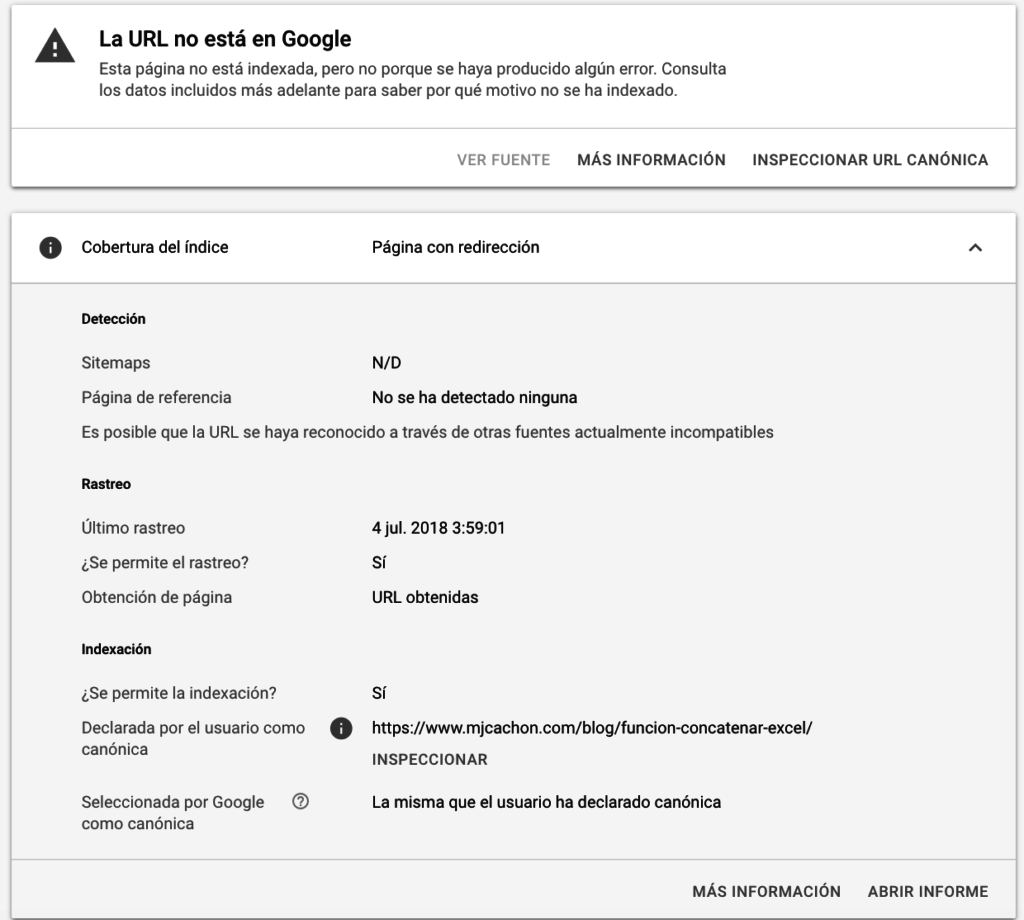
Ejemplo 8: Cuando una url redirige a una url 404
Otro caso que puede ocurrir voluntaria o involuntariamente, mandar redirecciones a urls que responden 404.
En este caso, cuando inspeccionemos la url nos indicará que existe una anomalía en el rastreo, ya que al llegar al destino, no puede obtenerse ningún contenido.
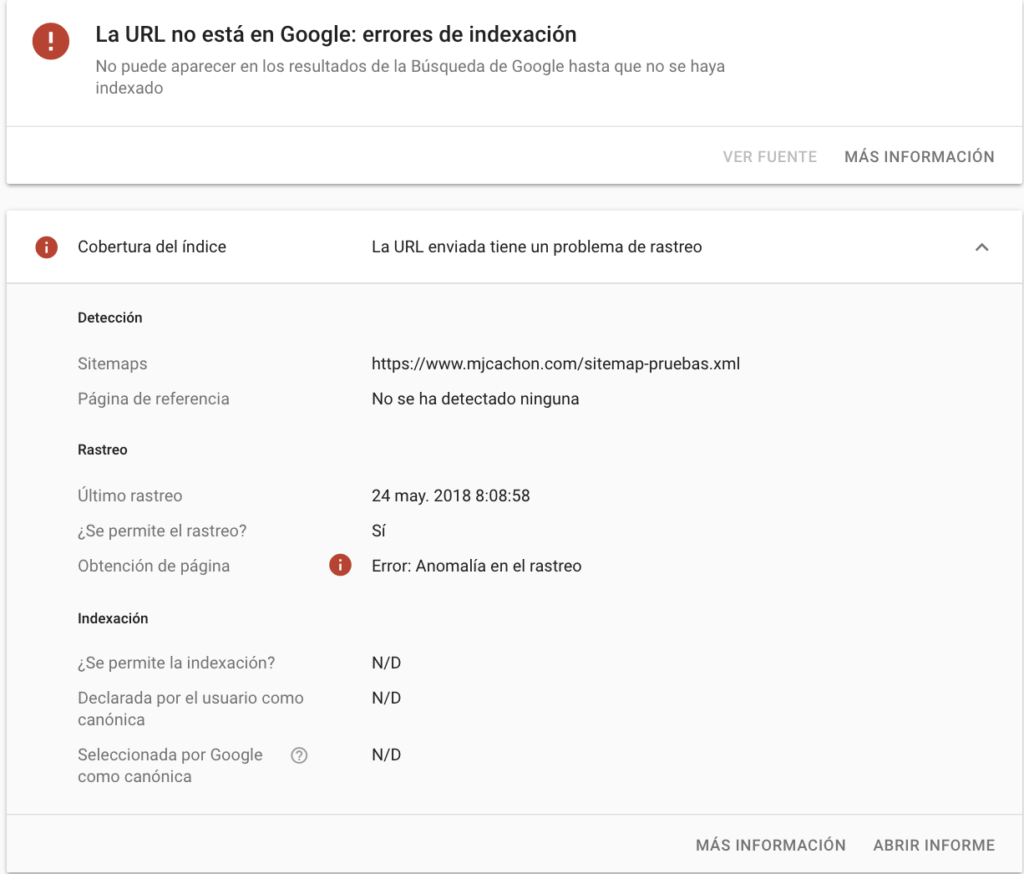
Ejemplo 9: Cuando una url tiene meta unavaliable after
Me gusta este ejemplo porque no es muy típico y nos desvela un detalle interesante. El inspector detecta que la url está disponible para rastreo y también para indexación.
La etiqueta meta unavaliable after, indica una fecha a partir de la cual, la url se desindexa de Google.

Ejemplo 10: Cuando queremos detectar urls para inspeccionar
Nos podemos ir a Cobertura del Índice y ver las urls que tenemos en cada sección

- Urls con Error
- Urls válidas con advertencias
- Urls válidas
- Urls Excluidas
Podemos analizar todas, pero nos deberíamos centrar en errores y excluidas.
Cada una de ellas nos mostrará un listado con las casuísticas, por ejemplo, las de Errores
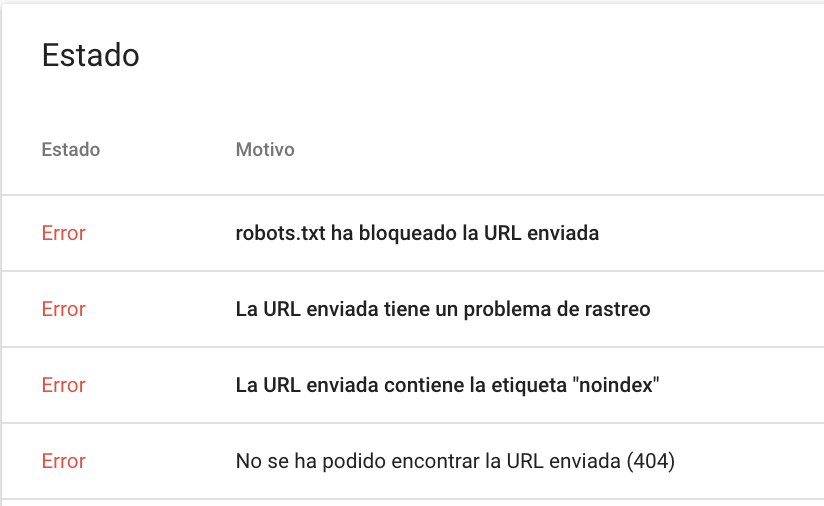
Ahora elegimos la de Noindex y Google Search Console nos mostrará los ejemplos de urls que cumplen este punto
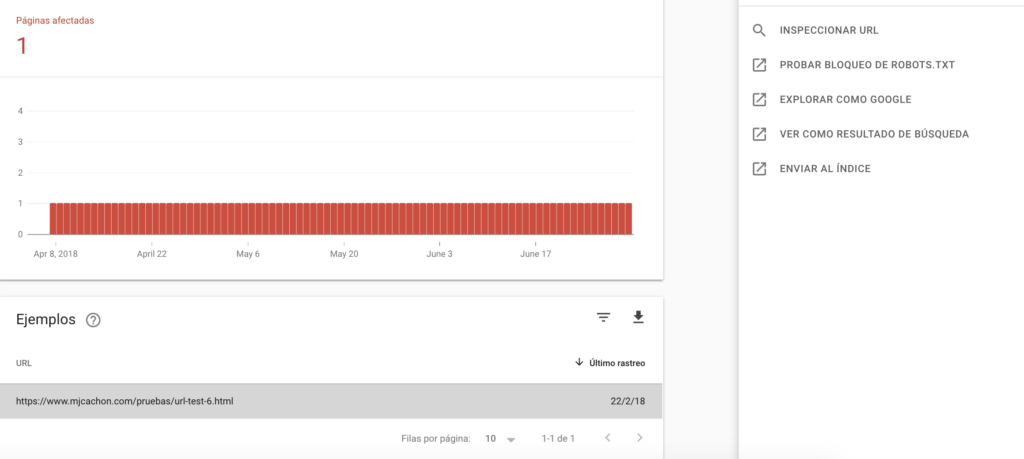
Desde aquí ya podemos inspeccionar la url o chequear otros aspectos como bloqueos de robots, ver como un resultado de búsqueda (comando site:) o incluso, solicitar que se indexe.
Por hoy, hasta aquí hemos llegado, si tenéis alguna idea de otras casuísticas, comentad 😀



Hola Mj!
Realmente, salvo lo de «página de referencia» toda la información que aporta el nuevo informe ya la teníamos disponible de forma dispersa en otros informes, ¿no? Por otro lado, la fecha de último rastreo no coincide con la del informe de cobertura que a su vez no coincide con la de los LOGs. Pero sin duda, todo lo que sea tener otra fuente de información oficial con la que atar cabos.. siempre es bienvenida.
Hola MJ,
tengo un caso un poco particular, o eso creo. Me aparece el mensaje «Se ha indexado aunque un archivo robots.txt la ha bloqueado». He estado investigando y en todos los sitios dicen lo mismo, No index y solucionado. Pero el caso es que esas páginas están en No Index. ¿Qué podría hacer?