
En los últimos tiempos hemos vivido muchas migraciones de distinto tipo, bien por idiosincrasias de proyectos que necesitan un rediseño o lavado de cara radical, bien porque además de lo anterior, se replantea la arquitectura de la información, se pasa a https o por otros motivos, hay un cambio de dominio.
En todos los casos, si no existe una planificación previa para llevar a cabo la migración en condiciones que garanticen la estabilidad, incluso, el crecimiento de tráfico, puede tener consecuencias de alto impacto para el proyecto web, respecto a indexación y tráfico, y sobre todo, en lo referente a negocio.
Posibles impactos SEO
Los impactos a los que se expone nuestro proyecto se pueden catalogar en estos grupos:
- Arquitectura de información y urls
- Contenidos
- Enlazado interno
- Maquetación y html
De este modo, en función de la migración en la que estemos inmerso, los cambios pueden ser de más o menos impacto, pero en muchas ocasiones, estos elementos se verán afectados.
Así, los tres primeros puntos pueden afectar a indexabilidad e indexación, pues cambios drásticos en la estructura de urls y en los contenidos, pueden hacernos menos accesibles y por otro lado, impactar en el nivel de indexación del que partíamos, y como consecuencia de perder indexación, podemos sufrir pérdidas de visibilidad y rankings.
Si nos paramos en la parte más puramente de html y etiquetados, esto nos podría provocar una pérdida generalizada de relevancia, si nos encontramos en escenarios de cambios masivos de etiquetas, por ejemplo.
El grado de impacto negativo puede variar en función de cómo se combinen las modificaciones de estos elementos
Proceso SEO para migraciones
En primer lugar, el proceso SEO parte de un estudio exhaustivo de los impactos anteriores y hacer una «foto» de la situación actual, estableciendo métricas de seguimiento por cada área SEO específica.
- Crawleo
- WPO
- Indexación
- Rankings brand + no-brand
- Tráfico por canales + tráfico orgánico
- Popularidad y enlaces entrantes
En seguro lugar, si es preciso hacer redirecciones, será necesario hacer un mapeo específico y detallado de las urls que pasarán a quedarse antiguas:
- Urls con tráfico seo y directo
- Urls posicionadas
- Urls indexadas, al menos, las que «deban» estar
- Urls con enlaces entrantes
- Otros recursos posicionados: imágenes, pdf, etc.
La regla de oro es tratar de hacer redirecciones limpias de origen a destino, con un único salto y SIEMPRE al contenido más relevante posible.
Aquí entra en juego el tipo de migración en el que estemos inmersos: http a https, cambio de dominio y estructura de urls, cambio de estructura de urls,…
A este punto añadiría aspectos que pueden parecer nimios y pasar desapercibidos y son de gran importancia:
- Comportamiento de las Urls canonicas como «index.php» y demás variaciones
- Comportamiento de Urls acabadas con o sin «/».
- Comportamiento de Urls con o sin «www»
Wayback Machine en Migraciones SEO
¿Y cuándo caes en un proyecto que no es tuyo y te enfrentas al reto de recuperar una gran caída de tráfico?
Para empezar puedes leer el post de Aleyda sobre cómo recuperarte de un drop de tráfico post migración, que cuenta paso a paso cómo no entrar en pánico y da tips de por dónde empezar a priorizar.
Por nuestro lado, vamos a ofrecer varios trucos con la herramienta Wayback Machine, de cara a tratar de chequear el estado de las urls antiguas y cómo remontar el vuelo, después de haber hecho ya las comprobaciones más obvias:
- Descartar errores de robots.txt y noindex
- Descartar errores de medición
- Detectar páginas con más pérdidas
- Chequear redirects
- Comparar estructura pre-migrar y post-migrar
- Comparar etiquetas pre-migrar y post-migrar
Añadir una web a Wayback Machine antes de la migración
Como ya comentábamos en el post de Wayback Machine como herramienta SEO un truco interesante puede ser enviar a Wayback Machine la web, antes de que migre, para tener una «copia» del estado previo a migrar y poder hacer comprobaciones casi «real time».
http://web.archive.org/save/http://la-url-que-quieres-guardar
O desde la portada, añadiendo en «Save Page Now»

Y ya tendríamos nuestra «muesca» temporal en las capturas de Wayback Machine

En otros casos, se puede bloquear al bot de Wayback Machine para que no rastree nuestro sitio, ya sea por temas de seguridad, privacidad, rendimiento….¡o manía!
Se puede añadir esta línea al fichero robots.txt:
User-agent: ia_archiver Disallow: /
Urls totales crawleadas en Wayback Machine
Si queremos tener todas las urls archivadas en Wayback Machine, que lleva crawleando sitios desde 1996, podremos usar este atajo:
https://web.archive.org/web/*/mjcachon.es*
Añadiendo el dominio elegido, tendremos un listado de todas las urls de las que dispone copia Wayback Machine.
Quizás esto nos resulte útil para subir a Screaming Frog en modo lista y hacer una comprobación en bulk del status code y tratar de detectar redirecciones sin hacer o enviadas a un mal destino.
Si bien es cierto este punto no nos aclararía qué estructura tenían antes de migrar, podemos navegar por Wayback Machine, por la copia más cercana al momento previo a migrar y extraer:
- Mapa Web
- Menú de páginas principales
Podemos usar alguno de estos métodos bastante sencillos:
- Plugin Scrape Similar
- Excel SEO Tools
- Función Import Xml de google spreadsheets, con expresiones Xpath.

Nuestra lista básica de xpath para SEO:

Para profundizar y seguir aprendiendo a usar expresiones Xpath, hay recursos facilitos y muy útiles:
- http://seotoolsforexcel.com/xpath-and-chrome-devtools/
- http://seotoolsforexcel.com/xpathonurl/
- http://www.internetmarketinginc.com/blog/power-xpath-seo/
- https://www.optimizesmart.com/data-scraping-guide-for-seo/
- https://www.distilled.net/blog/distilled/guide-to-google-docs-importxml/
Analizar estado de las etiquetas pre-migración
Una vez que tenemos las urls principales de la estructura, podremos chequear sus etiquetas más relevantes de cara a SEO y tener el antes y el después:
- Title
- Description
- H1
- Meta Robots
- Meta Canonical
Abrimos Screaming Frog en modo lista y pegamos las urls y podremos observar el estado que tenían las etiquetas principales
Como se puede ver, ya había un «noindex» en una de las urls 🙂

De manera alternativa, también podemos configurar Screaming para añadir en el Custom Extractor instrucciones para extraer los elementos de forma personalizada y específica
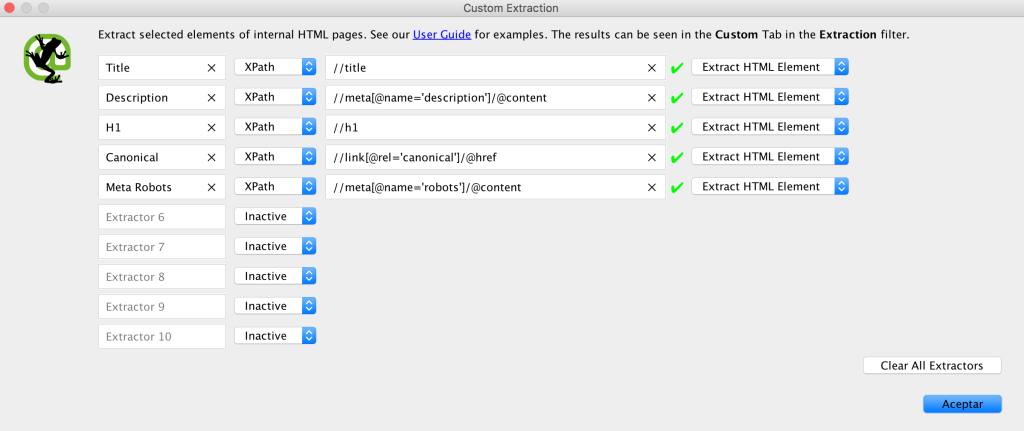
Analizar Sitemap antiguo con Screaming Frog
Ahora bien, si por lo que sea tienes problemas para completar el listado de urls top tirando de Analytics, las urls indexadas y demás método, quizás puedas llegar al sitemap antiguo a través de Wayback Machine.
Con dar con la url, Screaming hará el resto. Puedes probar primero a mirar el robots.txt del sitio en cuestión desde Wayback Machine o bien probar la ruta estandar «sitemap.xml» y ver si hay suerte.
Esta funcionalidad de Screaming Frog está muy bien <3

Añadimos el Sitemap y a chequear status code del sitemap antiguo
¿Siguen indexadas esas urls? ¿Y qué aspecto tenían?
Y para terminar, un hack curioso, podemos comprobar con Url Profiler si las urls siguen o no indexadas, al menos las más importantes de nuestro análisis.
Para este punto, usaremos las urls finales, sin el resto de url de archive

En el caso de que no estén indexadas, podemos comprobar en bulk, qué aspecto tenían dichas urls o landings, para determinar si el contenido era importante o no, o si a alguien se le ha olvidado replicarlas en la nueva web.
Para este punto, debemos usar las urls antiguas, es decir, las que anidan con la url de archive, que es el único lugar donde queda una copia del contenido

La herramienta nos creará una carpeta con los ficheros png de cada url y el aspecto que tenían, según la copia almacenada en Wayback Machine, ¿mola o qué?
Pues este es el friki post del 15 de agosto, día festivo y patrón de la Migración SEO



En el caso que descargues las urls como es en el caso de https://web.archive.org/web/*/mjcachon.es* y salgan paginadas por ser un site grande… ¿nos das algún consejo para scrapear en bulk?
🙂
Amigo!!
No he encontrado formas muy fáciles, para mi al menos que no sé programación ni tengo un background técnico fuerte.
Sé que hay un script aquí –> https://github.com/hartator/wayback-machine-downloader
Por otro lado, estoy intentando probar esto a ver si merece la pena pagar los 10 dólares o no 🙂 https://archivescraper.net/
Y la forma «rápida» ha sido usando scrape similar y paginando, esto para hacerlo en análisis de paths concretos o zonas de la web acotadas, va perfecto, pero claro, para una web que tenga miles de urls, se te va de las manos 😀
Abrazo crack