
[Este post fue escrito originalmente por Saskia Moreno, en su paso por la agencia, antes llamada «Somos Mjcachon»]
Sí estas empezando en SEO, seguro que ya has oído hablar de la importancia que tienen las herramientas y lo necesarias que son en nuestro día a día. Rastrear o crawlear una página web es una de las primeras cosas que haremos en cualquier proyecto SEO.
Nosotros usamos Screaming Frog, que tiene una versión gratuita limitada a 500 URLs entre otras características, pero si vas en serio te recomendamos que compres la licencia con la que tendrás acceso a todas las funcionalidades.
Lo primero que vamos a hacer es aprender a Configurar Screaming Frog de la manera correcta, entendiendo todas sus funcionalidades y exprimiendo a tope la herramienta.
Para saber más, puedes consultar el post Qué es y cómo funciona Screaming Frog donde entramos en detalle sobre la herramienta.
¡Arrancamos!
Cómo usar Screaming Frog y configurar el Spider
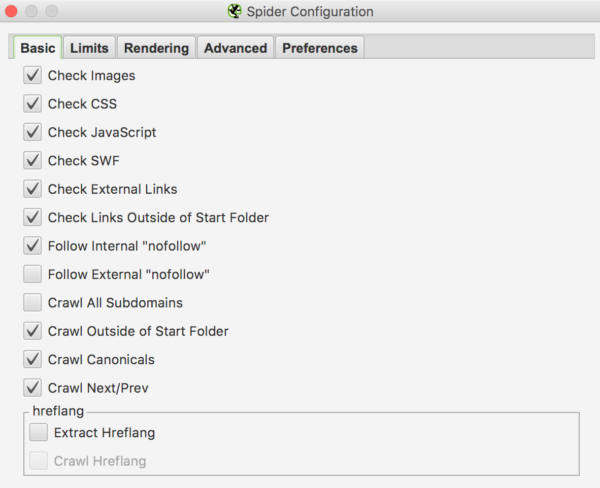
La configuración del Spider dependerá de lo que quieras saber y extraer de la web que vas a analizar. Vamos a por la configuración de la pestaña Basic.
 (Screaming Frog versión 9)
(Screaming Frog versión 9)
☑️ Check images
☑️ Check CSS
☑️ Check Javascript
☑️ Check SWF
Estos 4 campos se refieren a que vamos a rastrear de nuestra web las URLs de imágenes y archivos CSS, JS y SWF (aunque este último ya está algo obsoleto).
__________________________
☑️ Check External Links
Comprobamos los enlaces externos que hemos puesto en nuestra web. A veces incluso pueden ser ficheros CSS o JS externos.
__________________________
☑️ Check Links Outside of Start Folder
Nos saca un listado de enlaces a los que se apunta desde URLs que están fuera del directorio principal, es decir de los diferentes directorios que tiene mjcachon.com.
__________________________
☑️ Follow internal «nofollow» / Follow external «nofollow»
Nos interesa saber los enlaces internos que tiene nuestra web con la etiqueta «nofollow», con la que se le indica a Google que no siga dicho enlace como puede ocurrir con algunos links del footer, ej. política de privacidad y casos similares. Los externos, como puede ser un enlace a Twitter con «nofollow» no los marcamos.
__________________________
☑️ Crawl all subdomains
Esta función es la que debes marcar si quieres rastrear tu sitio web entero, incluyendo subdominios como: subdominio.ejemplo.com
Nosotros nos vamos a centrar solo en mjcachon.com sin tener en cuenta los subdominios y así optimizar por ahora solo el dominio principal, pero puedes hacerlo como más cómodo te sea.
__________________________
☑️ Crawl outside of start folder
Esto sí suele ser básico y útil, pues sirve para crawlear los directorios que se encuentran fuera del directorio que le hemos indicado para rastrear.
Por ejemplo queremos rastrear https://mjcachon.com.
Al habilitar esta opción, la rana entraría en otros directorios como: https://mjcachon.com/blog
__________________________
☑️ Crawl Canonicals
Crawlea los enlaces que hay dentro de las versiones canónicas de cada URL. Además, por defecto, Screaming Frog nos va a mostrar qué URLs contienen elementos canonical.
__________________________
☑️ Crawl Next/Prev
Busca los enlaces rel=»next» y rel=»prev» y rastrea los links que hay dentro de ellos.
__________________________
☑️ Extract hreflang
☑️ Crawl hreflang
Marca estas opciones si tienes una web en varios idiomas y se usa el marcado hreflang. La primera (Extract hreflang) tan solo extraerá el marcado hreflang para analizar si está bien implementado y la segunda (Crawl hreflang) además rastreará los enlaces que haya dentro de las URLs. Si quieres indagar más en el tema del hreflang, este post de cómo revisar el hreflang con Screaming Frog te ayudará.
¡Muy bien, casi está! Solo quedan unos pequeños detalles y lo tenemos todo listo.

De estas dos pestañas, Limits y Rendering, es importante que te quedes con lo siguiente:
☑️ Limit Crawl Total
Lo cambiarás si quieres crawlear menos de 5.000.000 de URLs, vamos, si no quieres crawlear la web entera.
__________________________
☑️ Limit Max Folder Depth
Se refiere a qué niveles de profundidad de directorios quieres que rastree la web desde la home.
Por ejemplo: mjcachon.com o ir otro directorio más profundo: mjcachon.com/servicios
__________________________
☑️ Limit Number of Query Strings
Si tenemos un sitio enorme con muchos parámetros, cosa que pasa mucho en el e-commerce y sitios que tienen filtros de búsqueda, podemos limitar el número de parámetros para que la rana rastree más rápido.
Por ej. esta URL contiene 6 parámetros, empiezan en el símbolo “?” y son separados por “&”:
https://www.fotocasa.es/es/alquiler/casas/madrid-provincia/todas-las-zonas/l?latitude=40.415&longitude=-3.71036&minPrice=200&minRooms=1&combinedLocationIds=724,14,28,0,0,0,0,0,0&gridType=3
Estos parámetros son ocasionados por los filtros que contiene la web de Fotocasa.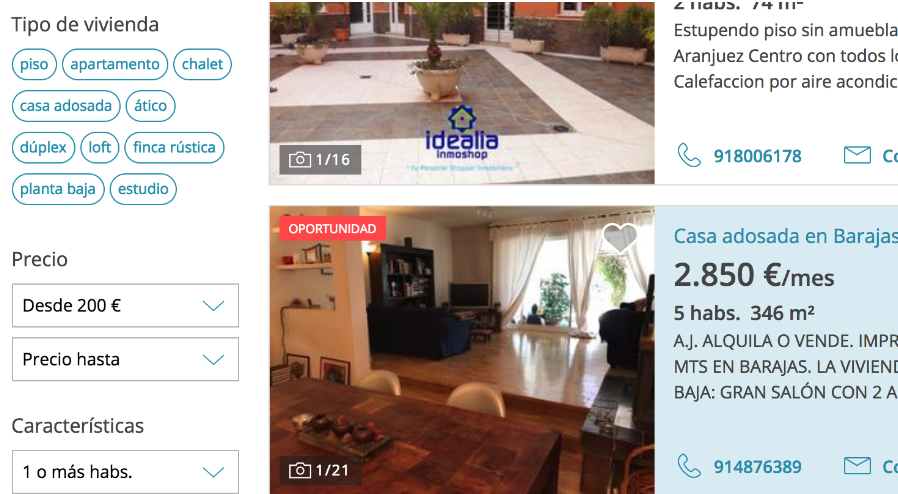
Para evitar que nos muestre las URLs con parámetros, marcamos la casilla con un 0 (cero).
También podemos configurar qué parámetros excluir desde la opción “URL Rewriting”.
Imaginemos que queremos mantener todos los parámetros y nos interesa quitar tan solo el parámetro de ?replytocom.
Vamos al menú de Screaming Frog > Configuration > URL Rewriting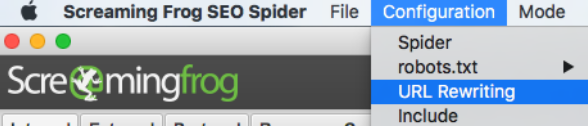
Insertamos nuestro parámetro a excluir o uno por línea si tenemos varios parámetros, sin “?” y hasta “=”, en otras palabras: el nombre del parámetro.
Al dar a “start” a la hora de rastrear, este parámetro ya no aparecerá en los resultados del crawleo de Screaming Frog.
__________________________
Perfecto. 🙌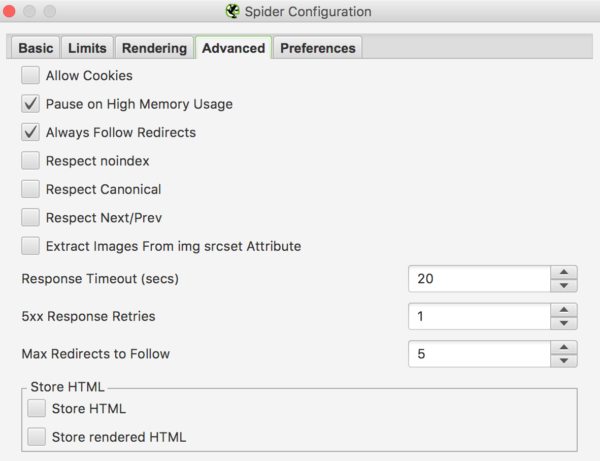
De la última pestaña Advanced te mencionamos lo importante aquí abajo y Preferences la dejaremos tal como está.
☑️ Always Follow Redirects
Queremos que Screaming Frog siga, partiendo desde una URL que redirige con un código 301 o 302 por ejemplo, toda la secuencia de posibles redirecciones. De este modo luego nos mostrará la cadena de redirecciones que tiene esa URL inicial.
Ejemplo: URL 1 con redirección 301 ⟶ URL 2 con redirección 301 ⟶ URL 3, la URL final correcta
__________________________
☑️ 5xx Response Retries
Está bien ponerle 1 o 2 intentos en caso de que, justo cuando estemos analizando la web, haya un error de servidor 5xx temporal. Así el crawler lo intentará otra vez. En la opción de encima Response Timeout (secs) especificamos cuándo damos por perdida la batalla contra ese error 5xx. A los 20 segundos dejará de intentar entrar en la URL.
__________________________
☑️ Max Redirects to Follow
Aquí especificamos el largo de la cadena de redirecciones que acabamos de comentar en Always Follow Redirects. En otras palabras, le indicamos que como mucho nos saque hasta las 5 primeras URLs de una cadena de redirecciones.
__________________________
¡Bravo! Ya has pasado el primer tramo. Ahora solo tienes que darle al botón de Start y empezará a crawlear…
Según el tamaño de la web que estés crawleando, el Spider tardará más o menos en terminar de mostrar todos los resultados. Si se trata de una web muy grande de miles de enlaces, es posible que la herramienta tarde varias horas dependiendo también de la potencia de tu PC, así que… paciencia. 🙂
En el próximo artículo detallaremos qué información obtenemos de nuestro crawleo con Screaming Frog y cómo analizarla y usarla para nuestra auditoría.
Mientras tanto puedes mirar la vida pasar o ir aprendiendo estos trucos SEO que seguro no sabías que se podían hacer con Screaming.
Otros contenidos sobre Screaming Frog:
Cómo usar Screaming Frog, paso a paso
Cómo usar custom extraction y search en Screaming Frog



Hola! Quería saber que opináis sobre establecer la configuración de rendering del spider en Old AJAX Crawling Scheme. Ya que para sitios grandes, su rastreo de urls/s es más rápido que la opción de Text Only.
¡¡Gracias!!