
Seguimos con contenidos de «la rana», esta vez para contar como podemos seguir el marcado hreflang de un proyecto.
Ya sabéis que Google nos recomienda marcar con hreflang proyectos internacionales, para indicar el idioma de cada versión, y cuando procede, si existe una orientación geográfica de país.
Dicho esto, es muy habitual que cualquier proyecto por sencillo que sea, tenga español e inglés como idiomas de base, y cada idioma, sus urls propias, con el contenido especificado en su correspondiente idioma.
Y por tanto, cada url debería contener, como mínimo, dos anotaciones idiomáticas: una que la autoreferencie y otra a su contenido equivalente o alternativo en el otro idioma.
Así tendríamos:
- Url ES: http://es.dominio.com
- Url EN: http://en.dominio.com
Donde podríamos marcar así:
<link rel="alternate" hreflang="es" href="http://es.dominio.com" />
<link rel="alternate" hreflang="en" href="http://en.dominio.com" />Si tenemos una página principal para seleccionar los idiomas o países, o bien, la home se redirige automáticamente a una url de idioma podemos hacer uso del marcado x-default
link rel="alternate" href="http://es.example.com/" hreflang="x-default"/>Esta anotación debe ser bidireccional entre urls y la podemos hacer:
- En el código fuente
- En los sitemaps
- En la cabecera HTTP
Hasta aquí, ¡nada nuevo!
(Puedes leer la documentación oficial tranquilamente aquí, pero proyectos hay muchos y esto se puede complicar muchíiiiiiisimo según el tamaño, los idiomas y los países que tengamos…)
Cómo saber qué urls tienen o no tienen marcado hreflang con Screaming Frog
Vamos a usar Screaming Frog para chequear todas las urls de un site y saber si están usando el marcado hreflang o no.
Podemos hacerlo de dos formas
- Crawleo completo usando Custom Search
- Crawleo en modo lista usando Custom Search
Vamos a explicar precisamente como configurar la opción Custom, indistintamente de el modo de crawleo que elijamos para analizar las urls
Lo primero es ir Configuración > Custom > Search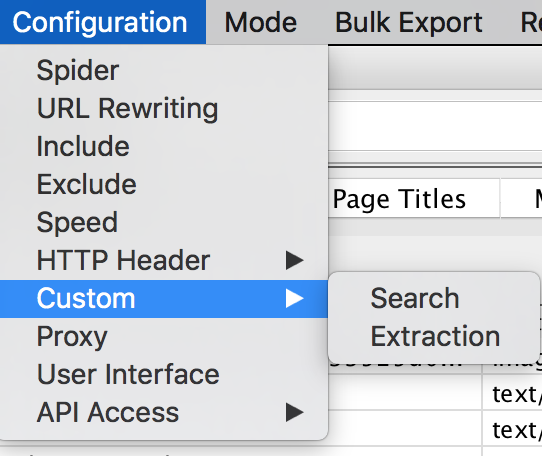
Y tendremos la opción de rellenar hasta 10 filtros, con la opción de «contiene» o «no contiene». Estos filtros, para Screaming Frog, es una instrucción tal que «busca si existen (o no) coincidencias en el código fuente de las urls que crawlees»
En este caso vamos a usarlo para buscar los marcados hreflang, pero imaginad que guay sería, otro ejemplo como, buscar si está el código analytics en todas las páginas, después de migrar…
Yo suelo poner un «contiene» y «no contiene», del mismo elemento que busco, así se donde está y donde no, al mismo tiempo.
Con hreflang, con el ejemplo que decíamos, quedaría así:
Después de que termine Screaming, tendremos la información en el interfaz habitual que conocemos, si queremos llegar al atajo más rápido, podemos usar el panel derecho, scroll y pestañas, hasta llegar a Custom y los filtros que hemos puesto:
Ya de un vistazo vemos dónde está y donde no, del total de urls con un porcentaje del total, que siempre es útil
Por supuesto, podremos exportar toda la información, filtro a filtro, en csv o excel, tanto desde el panel central, como desde la opción Bulk Export > Custom > Filtro que queramos
Cómo extraer qué urls tienen o no tienen marcado hreflang con Screaming Frog
También podemos usar Screaming Frog para extraer todas las urls de un site con su marcado hreflang.
Cuando trabajamos con clientes, podemos hacer la extracción al inicio del análisis y luego comprobar con Custom Search, si nuestra recomendación ya está implementada en el código o no.
Como antes, el crawleo y la extracción podemos ejectuarla de dos formas
- Crawleo completo usando Custom Extraction
- Crawleo en modo lista usando Custom Extraction
La idea es indicar los campos que queremos extraer, con los métodos que nos da Screaming, y capturar el html que nos interesa, para chequear que el marcado hreflang es correcto o no.
Lo primero es ir Configuración > Custom > Extraction
Y tendremos la opción de rellenar hasta 10 extractores, mediante varios tipos de instrucciones:
- CssPath: los selectores son los patrones utilizados para seleccionar los elementos, y según Screaming Frog, son a menudo el método más rápido para la extracción. Además de los selectores CSS puede incluir el campo atributo como opcional.
- Xpath: son consultas que analizan los nodos de un documento XML como por ejemplo HTML. Esta opción usa selectores y atributos para capturar los datos.
- Regex: una cadena especial de texto que se utiliza para hacer coincidir patrones con los datos. Este es uso más avanzado de todos.
Yo suelo usar xpath para extraer el html exacto, siguiendo el ejemplo del hreflang, quedaría tal que así:
Lo que pongamos como nombre de campo, en vez de Extractor 1 y Extractor 2, es el nombre del campo que veremos en la interfaz y en el informe posterior que descarguemos.
Ahora podemos extraer la información completa de varias formas:
- Desde el panel / pestaña de Extraction y «Export»
- Desde Bulk Export > Custom > Extraction Inlinks
- Desde Internal All, es interesante tener la información de meta etiquetas, canonical, robots, etc, junto con la de hreflang, para confirmar que todo en conjunto, es correcto y no hay conflictos
Pues nuevamente, nuestra querida rana Screaming Frog, vuelve a nuestro rescate para hacernos la vida más fácil…
Y a vosotros, ¿se os ocurren otras formas o herramientas con las que acelerar comprobaciones masivas de hreflang?
Más contenidos sobre Screaming Frog:
Analizar contenido duplicado con Screaming FrogPáginas huérfanas con Screaming Frog



Gracias, muy útil 😉