
De los creadores de URLProfiler, llega a nuestras vidas SEO otro software que dará mucho que hablar, se trata del crawler de escritorio SiteBulb (revisada la versión 1.0.11)
En su web sitebulb.com, enumera lo que para mi ya es una gran declaración de intenciones:
- Performance: auditoría de rendimiento y velocidad de carga, tanto desktop como mobile, con métricas de mucho valor (TTFB, Latencia, crawl depth, renderizado, y todo junto a recomendaciones de mejora…)
- Indexación: estado de la indexación del sitio para detectar problemáticas o zonas indexables con dificultades, manejo de robots.txt, detección de errores en canonicals y meta robots,…
- Internacional: podrás validar el marcado hreflang para detectar si existen etiquetas que no cumplen los requisitos de reciprocidad o tiene códigos inconsistentes, incluidos los sitemaps 😀 Esta opción se verá en otro post 🙂
- Crawl: el crawler friendly que te ayuda a detectar problemas de rastreo, profundidad, cuellos de botella y demás aspectos ineficientes que pueden estar perjudicando tu proyecto (crawl map y uncrawled urls, son 2 de sus funciones top)
- Internal urls: descubre todas las páginas y recursos del site a lo largo de la estructura web y podrás obtener una lectura completa de cómo se distribuyen las tipologías de contenidos, a qué nivel de profundidad y con qué otros elementos, como paginación.
- Links: optimizar el flujo de enlazado interno, asegurándonos que potenciamos las páginas más importantes de nuestro proyecto, es el mantra de esta sección. Podrás analizar enlaces rotos, con nofollow, redirigidos, por nivel de profundidad e incluso por tipología de página…. muy potente!
- On Page: en esta sección podrás ahondar en toda la parte de contenidos y de etiquetados más conocidos en SEO, identificar errores o duplicidades, thin content y con otra feature chula, como es el grado de legibilidad de los contenidos y el análisis de sentimiento.
- XML Sitemaps: mantener sitemaps limpios y ordenados, chequear el grado de indexación de los sitemaps integrando Google Search Console.
- Resources: todos los recursos y sus códigos de respuesta o situación en la que se encuentran, radiografía de la salud del sitio.
- AMP: otra novedad que les diferencia de otros crawlers, validar que las páginas AMP están funcionando correctamente o no, que son accesibles, rastreables e indexables, entre otras cosas. Esta opción se verá en otro post 🙂
- Search Traffic: ¿qué pasa cuando mezclas datos de crawleo con datos de tráfico? Pues que sacas insights de mucho valor, como detectar páginas indexadas sin tráfico.
BOOM!
Bueno, no me enrollo más por aquí porque vamos a ver paso a paso qué funcionalidades trae consigo, usando la beta a la que hemos tenido acceso.
Here we go!
Configurando la auditoría del sitio con Sitebulb
Lo primero es lo primero, elegimos el nombre del proyecto y la url que queremos analizar.
Cada vez que hagamos un crawleo, se guardará en nuestro proyecto, con la tremenda utilidad que tiene esto si tenemos proyectos recurrentes o trabajamos el SEO de alguna web mes a mes.
También es útil en el caso de migraciones, para controlar el antes y el después.
Una vez le demos a «Save and Continue», la herramienta procederá a hacer un pre-audit y nos habilitará el tipo de audit que queremos realizar, pudiendo elegir entre:
- Standard: para la mayoría de sitios
- Sample: para sitios muy grandes, crawlear una muestra, o bien, la primera vez que crawleas un sitio y quieres echar un vistazo rápido a los datos.

Y aquí ya podemos hacer varias configuraciones básicas:
- Análisis de Site Speed, para obtener info de Performance (necesita tirar del Page Resource, también).
- Mobile Friendly, para ver si las urls son bien renderizadas y obtener si son friendlys o no (necesita tirar del Site Speed y del Page Resource, también). Esto requiere elegir Javascript Crawl 🙂
- Page Resource: crawleo de todo, html, css, imágenes…
- Amp Analysis: si sabes que no tienes AMP, pues no la marques 🙂
- International: ídem que lo anterior, chequea implementaciones hreflang
- XML Sitemaps: al marcarlo, la herramienta auto-detecta las urls correspondientes (por ejemplo del robots.txt) y te deja añadir las que quieras de forma manual.
- De manera opcional puedes vincular Google Analytics y/o Google Search Console
- Settings del crawler: tipo, tiempo del render, url por segundo y respetar (o no) las directivas meta robots.
Con esto hecho, podemos pasar a configurar las opciones avanzadas:
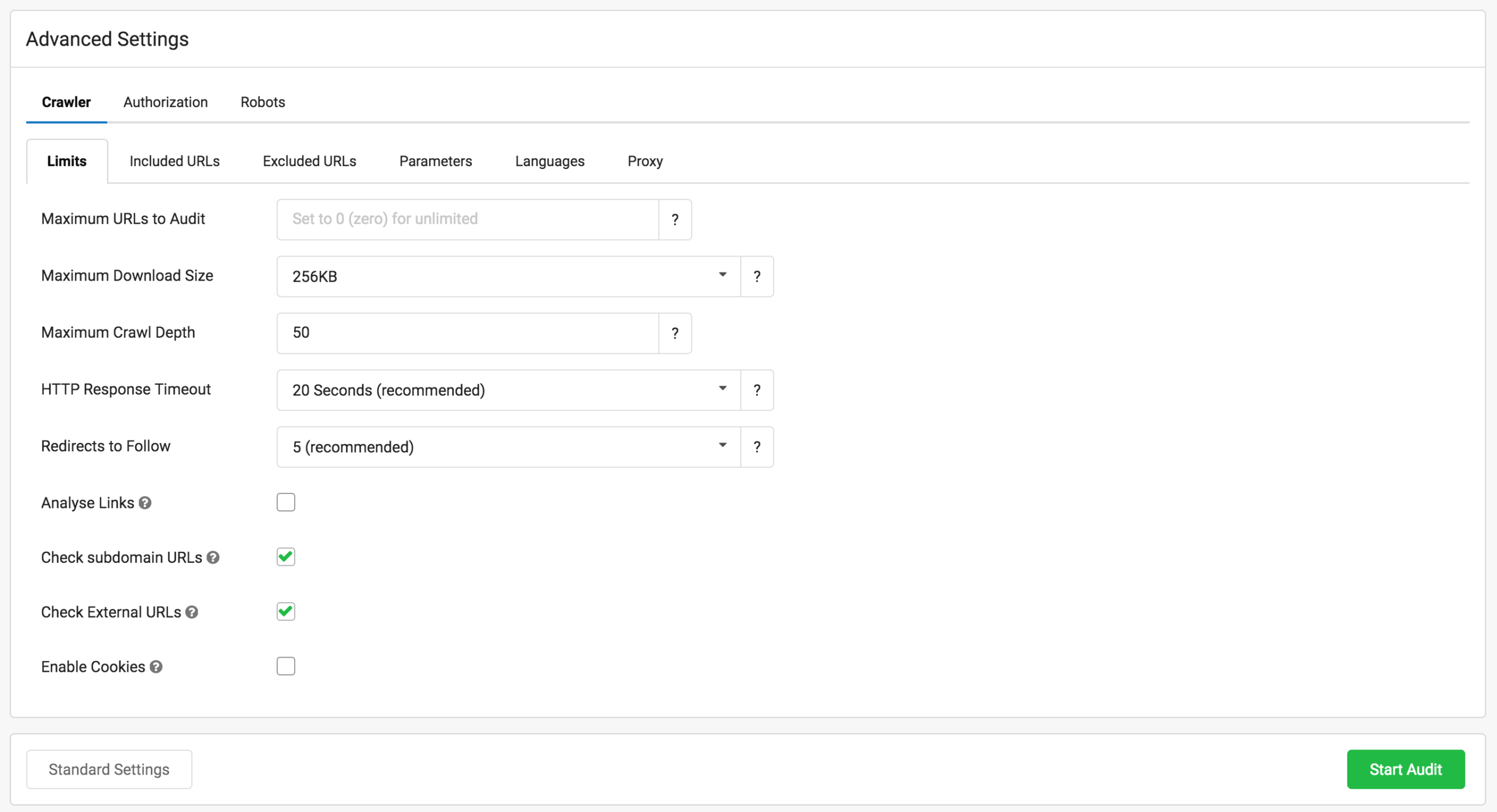
Pestaña Crawler
- Limits:
- Maximum urls: limitamos al número que queramos, o ponemos el número cero, para indicar «ilimitadas»
- Maximun Download size: tamaño máximo de descarga.
- Maximum Crawl Depth: la profundidad máxima de niveles a crawlear
- Http Response Timout: antes de que un recurso solicitado responda timeout, el crawler esperará este tiempo.
- Redirects to follow: número máximo de redirecciones que el crawler seguirá
- Analyse links: analizará enlaces internos de entrada y salida y sus textos ancla.
- Check Subdomains Urls: chequeará el status de urls de subdominios encontrados
- Check External Urls: chequeará el status de los links externos
- Enable Cookies: se puede emular rastreo con cookies.
- Included / Excluded Urls: para incluir o excluir patrones de urls, usando las mismas reglas que el robots.txt, sin tener que añadir Disallow ni Allow, tan solo los path o patrones con wildcards que quieras restringir o permitir.
- Parameters: podemos excluir todas las urls con parámetros desde esta opción o indicar cuáles específicamente no rastrear. Lo suyo es que si, por ejemplo, la paginación se monta con parámetros, los rastreemos.
- Languages: para sitios internacionales que puedan redirigir por locale del navegador o por accept language, puede configurarse específicamente esta opción.
- Proxy: si queremos hacer el rastreo con un proxy, pues podremos configurar en este punto los datos
Pestaña Authorization
- Http Authentication: para rastrear sitios protegidos con contraseña, por ejemplo entornos de pre-prod
Pestaña Robots
- Respect Robots Directives: para respetar las etiquetas meta robots y canonical o no
- User Agent: para elegir qué user agent hace el rastreo
- Virtual Robots.txt: podemos usar el robots.txt actual del sitio a analizar o crear un robots.txt personalizado virtual contra el que lanzar el rastreo.
Resultados: View Audit
Tenemos un primer overview que ya actúa de atajo para ir a otras secciones, con los datos de urls rastreadas, internas y externas, recursos y las urls no crawleadas, así como los detalles de la configuración usada. Clicando en «View», nos lleva a una tabla donde analizar esa información filtrada
También vemos 3 aspectos que solemos mirar en todos los proyectos SEO, si se hace una correcta devolución de códigos de error antes urls que no existen, la canonización de www y sin www, y de http y https.
Los datos acumulados

En esta misma pantalla de Overview tenemos otras subsecciones muy interesantes, con gráficos clicables que te llevan a la info filtrada en cada caso:
- Crawled Urls by Depth: las urls crawleadas por nivel de navegación, pasando el ratón por encima de cualquier punto, nos da los datos acumulados por status code. Muy útil para ver de un vistazo si tenemos un buen flujo de enlazado interno para facilitar el rastreo.
- Http Status Code: distribución de status code total.
- Urls Segments: tipologías de páginas, internas, externas, recurso, amp, internacional…
- Url Type by Depth: esta gráfica me parece de mucho valor, pues tienes un desglose de tipo de contenido por nivel, ya que en otras herramientas únicamente arrastras el número total de urls

- Html Url Source: este gráfico también tiene valor de interés, pues te indica si las urls rastreadas están en sitemaps, en Analytics y en Search Console. De un vistazo 🙂
- Content Types: la distribución de tipos de contenido que responden 200 OK, html, javascript, css, etc.
Como estos módulos van a estar presentes en muchas de las secciones del dashboard, lo ilustraremos con imágenes según avancemos el post.
Internal
Tenemos summary y hints, siendo el primero el panel de uso de los datos y los gráficos, y Hints, los atajos con recomendaciones.
Así, por ejemplo, estos son los hints sobre el análisis de mi propia web
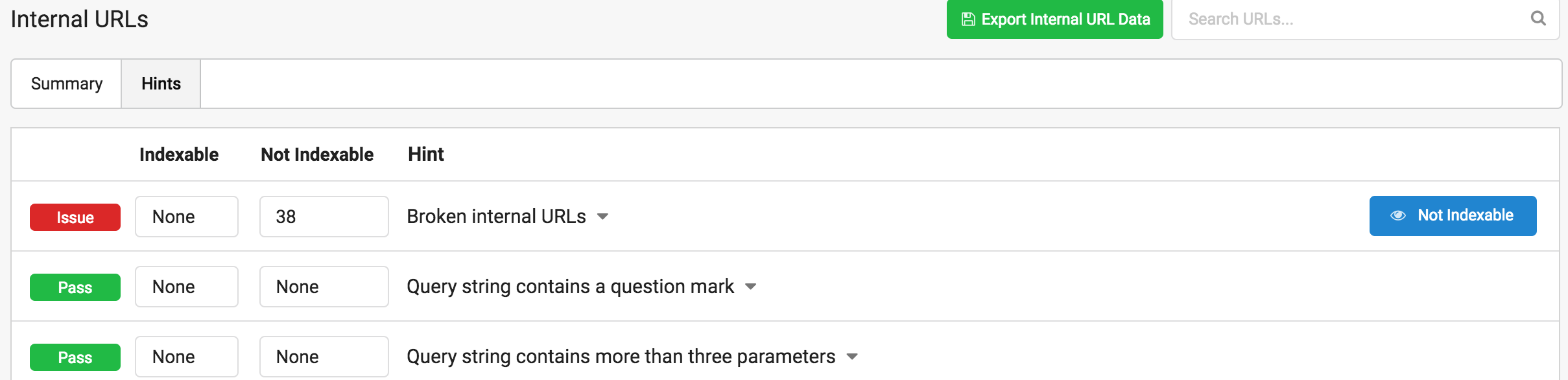
38 enlaces rotos, si pincho en esa línea me llevará a la tabla de links, con la url desde donde se enlazan para que los pueda corregir.
En esta sección nos podemos detener en el Crawl Depth por Status Code, que es muy visual y podemos clicar en cualquier parte del gráfico que nos llevará a la información filtrada, para consultar o descargar.
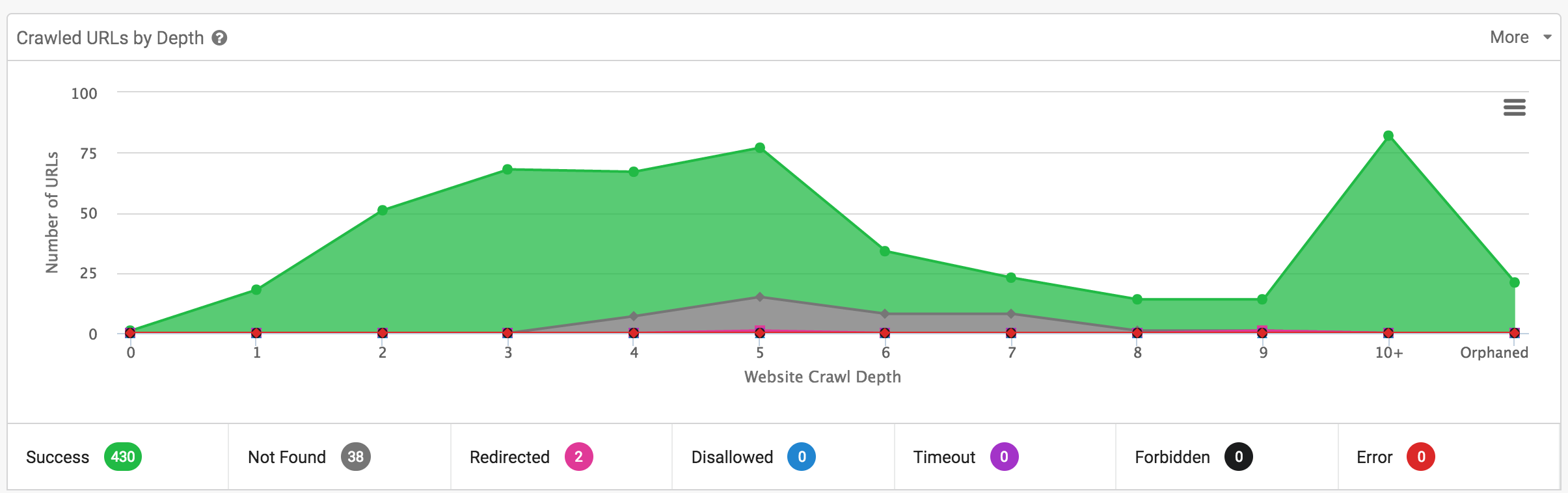
Se ven unas cuantas redirecciones en niveles algo más profundos, esto puede ser seguro por la doble migración que hice de .es a .com y de http a https. Por lo que esto puede ser solo el principio de las cosas que faltan por pulir.
Un dato interesante aquí también es el de las Orphaned Pages, páginas que no ha encontrado el crawler pero que existen dentro de la estructura.
En el caso de mi web, con el nuevo diseño, se generan muchas paginaciones que en algunos casos quedan muy profundas, y por otro lado, a la categorización del blog, que el rediseño ha provocado que no estén enlazadas desde ninguna parte lógica 🙂

Comentar también que los gráficos de Sitebulb pueden convertirse en tablas desde el botón «More», o descargarlo en formato png, jpg, svg, desde el menú hamburguesa.
También muy interesante ver de dónde ha obtenido el crawler las urls y la distribución de la paginación.
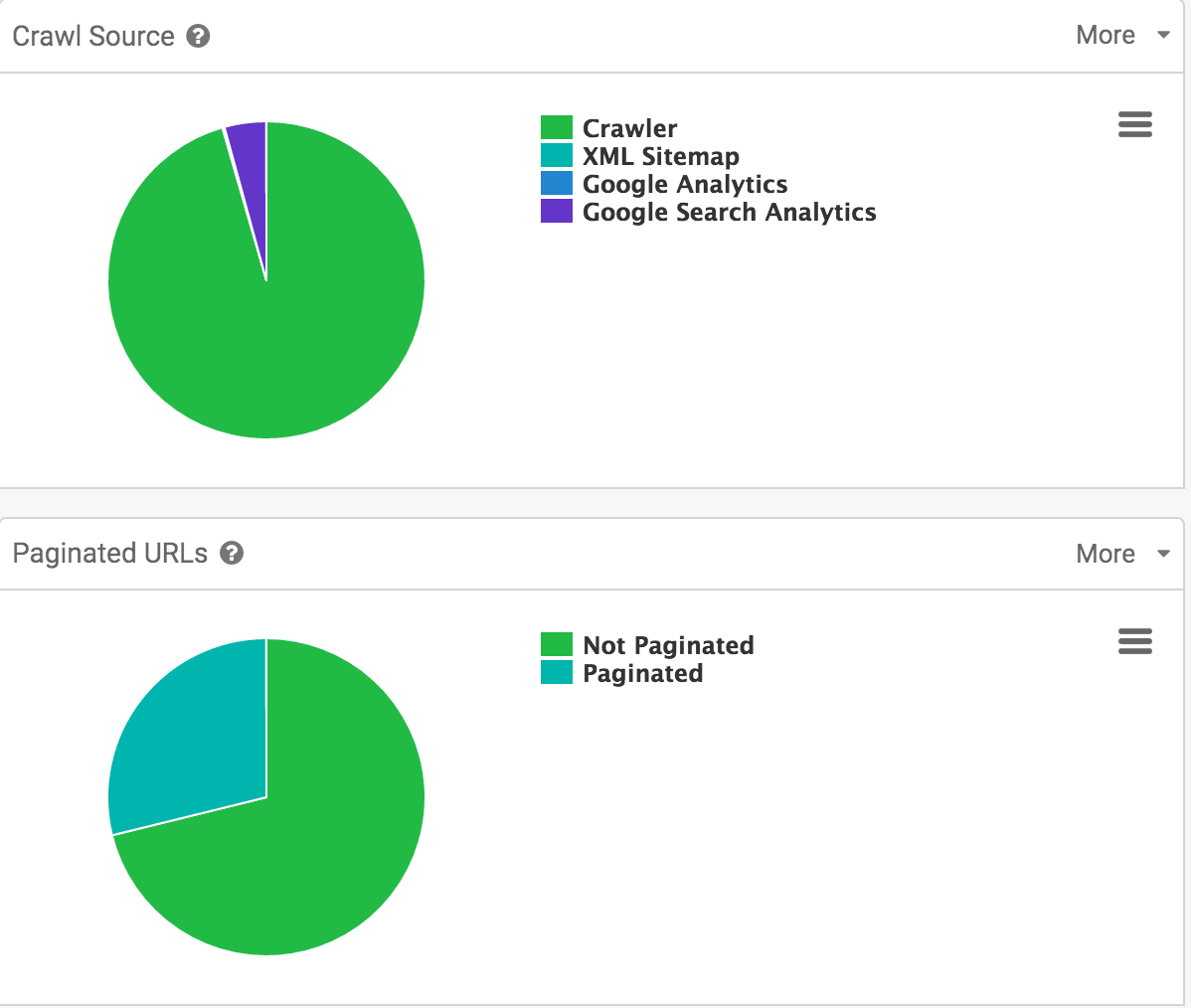
Como veis, hay páginas con tráfico según Google Search Console, a las que el crawler no llega en su rastreo, razón más que suficiente como para analizar qué mejoras se pueden implementar.
Por otro lado, para un sitio de contenido con no muchas páginas, existe un % de paginación excesivo. Así que el diseño y el SEO, como veis, han de ir de la mano siempre.
Adicionalmente agrega la parte de HTTPs, algo tremendamente útil en estos tiempos que corren
Links
Aquí tenemos el equivalente de Screaming Frog a «Internal All».
Tenemos un «Overview» con varias visualizaciones de la información, destacan
- Incoming Internal Following Links: que muestra nº de enlaces y nº de páginas que enlazan, en rangos de menos a más. Por ejemplo, hay 9 urls que no reciben enlaces, que corresponden a secciones nuevas que aún no tengo muy desarrolladas en el sitio y no las hemos potenciado mucho con enlaces.

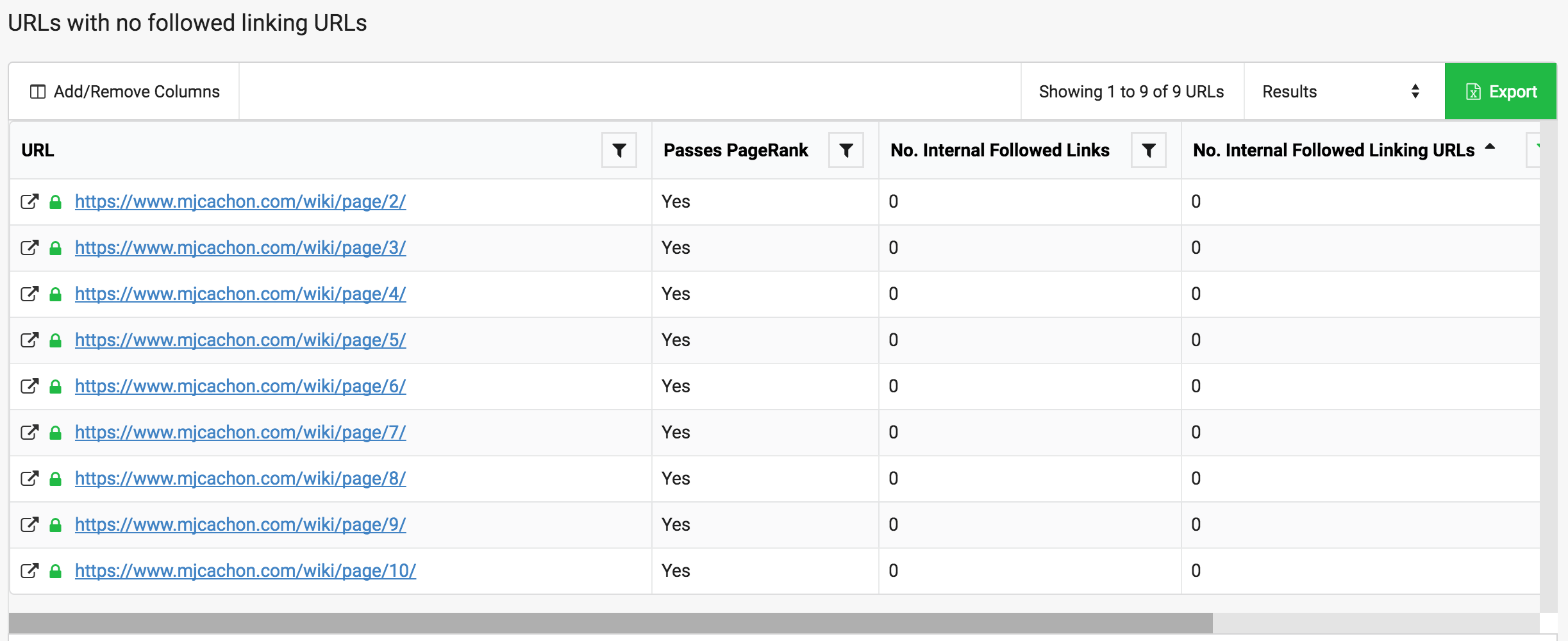
- Average Incoming Unique Internal Links: la media de enlaces internos que reciben las páginas por nivel de profundidad. Esto nos da un dato de mucho valor para entender nuestra arquitectura, desde el punto de vista de cómo de lejos o cerca están los contenidos entre sí y si realmente estamos creando un flujo consistente de enlazado interno para facilitar el rastreo entre niveles.

Sin duda otra de las partes en las que hay mejoras muy evidentes, partiendo de la base que la web ahora no tiene ni Breadcrumb 🙂
- Non HTML Content Types Receiving Internal Followed Links: si tienes formatos no HTML que reciben enlaces, puedes estar potencialmente perdiendo esa distribución interna del flujo de autoridad, page rank, filostros o como lo quieras llamar 😀

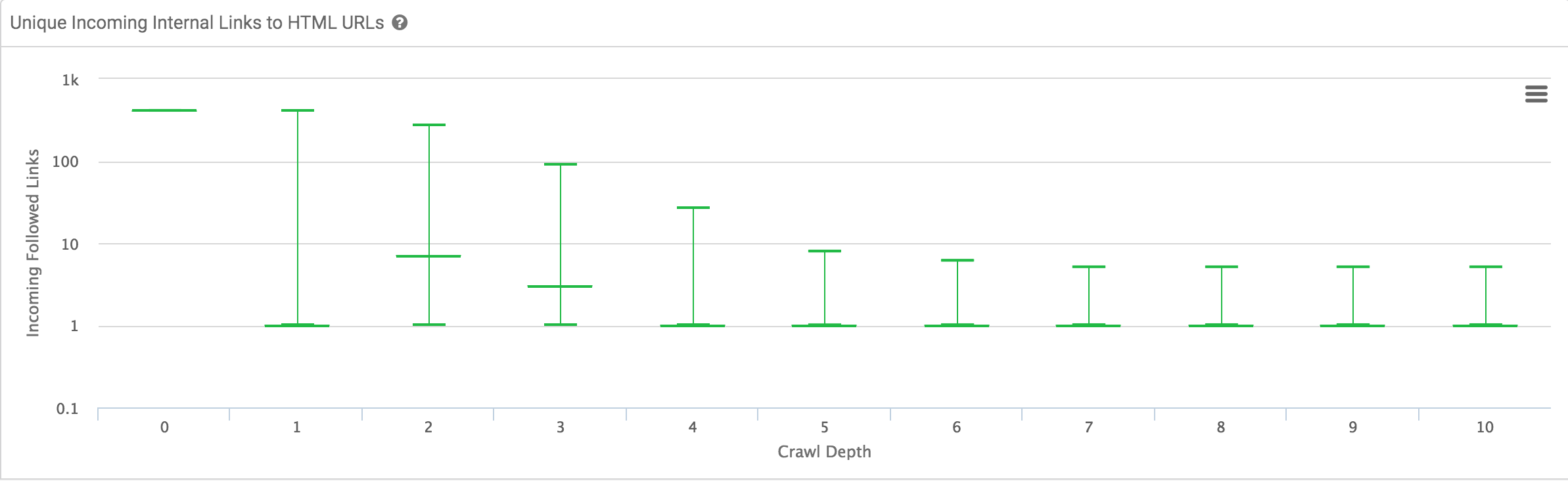
- Unique Incoming Internal Links to HTML Pages: unido a la anterior, en esta gráfica podemos también observar la distribución de links internos por nivel, con datos de mínimo, máximo y la mediana. Ambas gráficas nos puede dar pistas de mucho valor para detectar carencias de enlazado y de estructura.
Y más allá del Overview tenemos otras secciones como son Hints, Anchor Text y Top Pages, todo a nivel interno, se entiende.
Los Internal Hints, son los errores detectados que te los indica con colores de semáforo, tal y como hacen otras tools en sus crawleos y proyectos (Semrush y Sistrix, por ejemplo).

Como se puede observar, en esta lista hay acciones muy concretas para mejorar aspectos clave, como pueden ser:
- Links a urls no https: arrastrado de la migración
- Links sin anchor text y no alt text
- Urls con pocos enlaces internos o ninguno
- Errores en los href
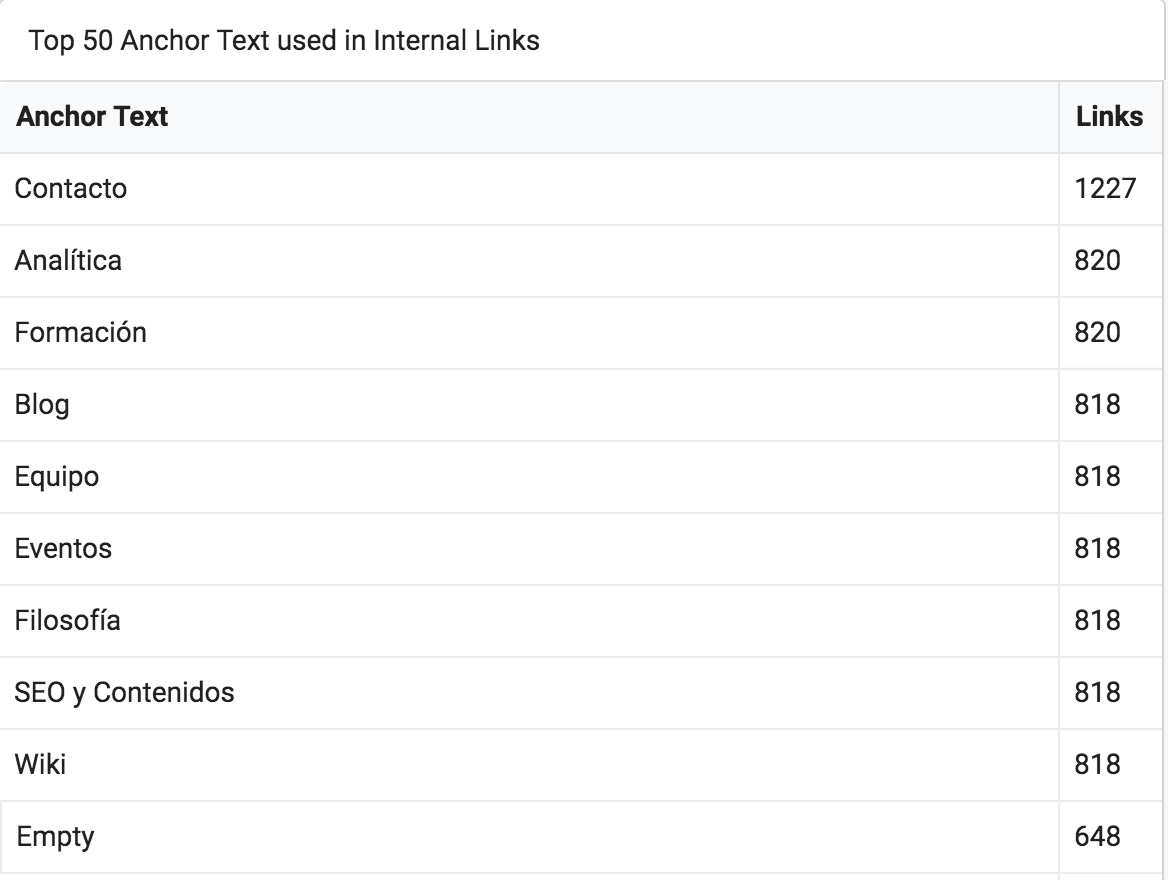
Y las otras dos secciones, Anchor Text y Top Pages, pues son las secciones más enlazadas, por anchor y url. Sobra decir que una de las páginas más enlazadas en muchos sites es…..¡el contacto!
Redirects
En esta parte, también podemos observar el crawleo por niveles, con las tipologías de redirección que existen.
La mayoría de redirecciones que se producen en los primeros niveles corresponden a recursos y a páginas externas.


Sin duda esta sección puede ser muy interesante para hacer el seguimiento de una migración, guardando los crawleos antes y después.
Si nos detenemos en los «Hints» que ofrece la herramienta, vemos los problemas más urgentes o evidentes a los que meter mano

El segundo punto nos indica que tenemos unas cuantas urls redirigiendo a un 404, un big fail que solemos ver en muchos proyectos (incluso en nuestra propia web, como este caso).
Indexation
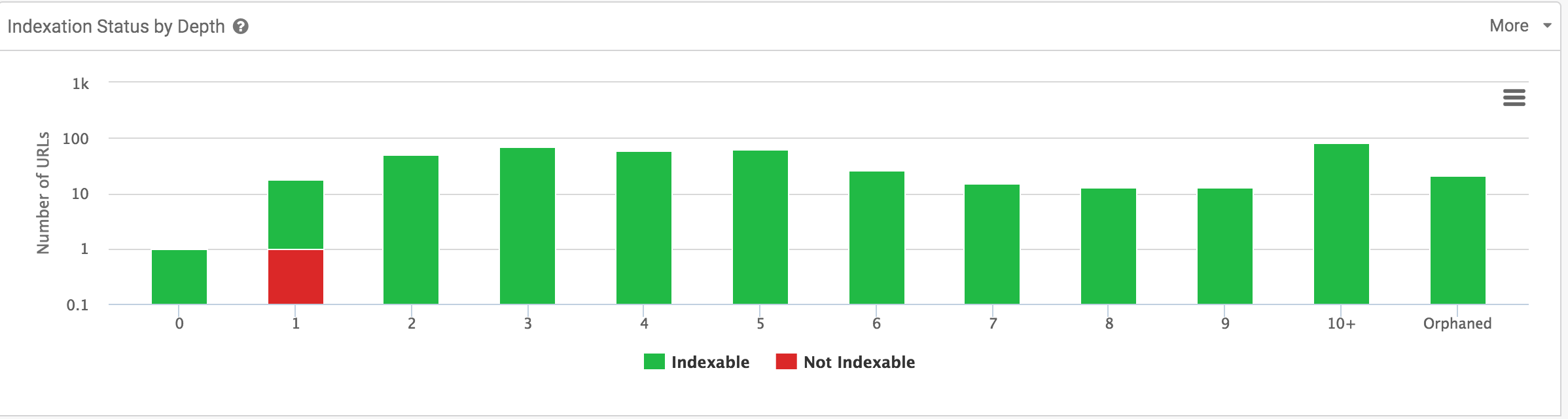
Una de las partes que más amigables pueden resultar, con un interfaz tan limpio y agrupando datos, podemos ver de un vistazo que tenemos una serie de páginas indexables y cuáles son no indexables.
El check de rastreo para confirmar si la web es accesible para los distintos user agent, respetando la configuración que hayamos establecido en los settings de robots.txt y la visualización del status de los canonical.
En mi web, no se ha hecho mucho SEO y prácticamente no hay páginas no indexables, por ahora, aprovechando el análisis, podemos tomar decisiones para indexar solo aquello que realmente genere demanda orgánica.

Para seguir profundizando en gráficos útiles, también añade estas otras distribuciones por nivel:
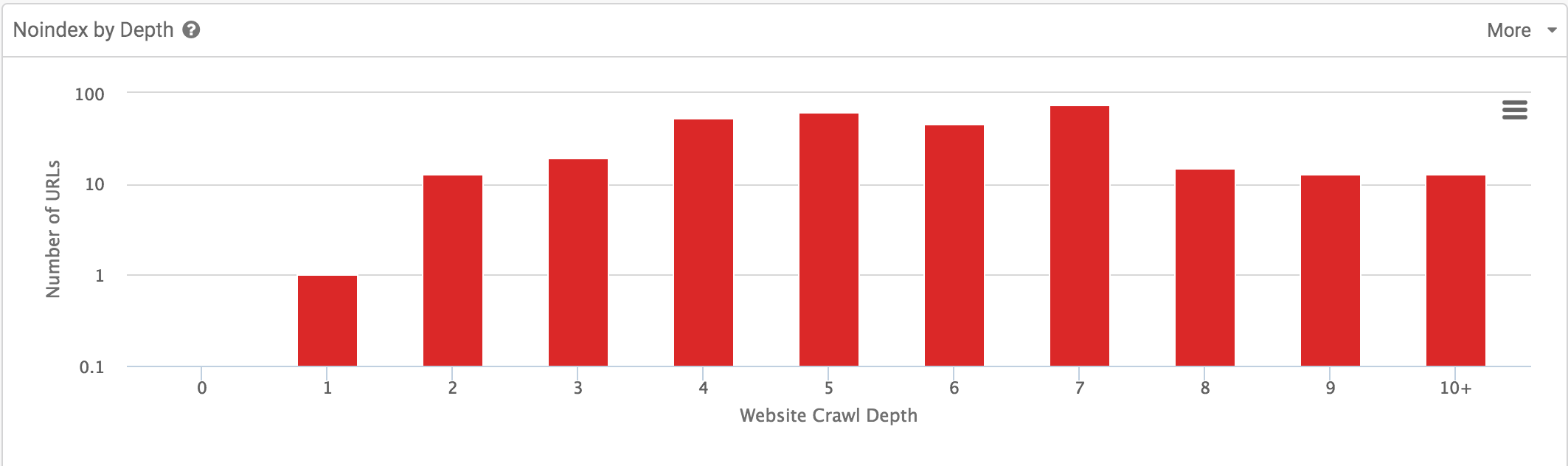
- Noindex by depth
- Disallowed by depth
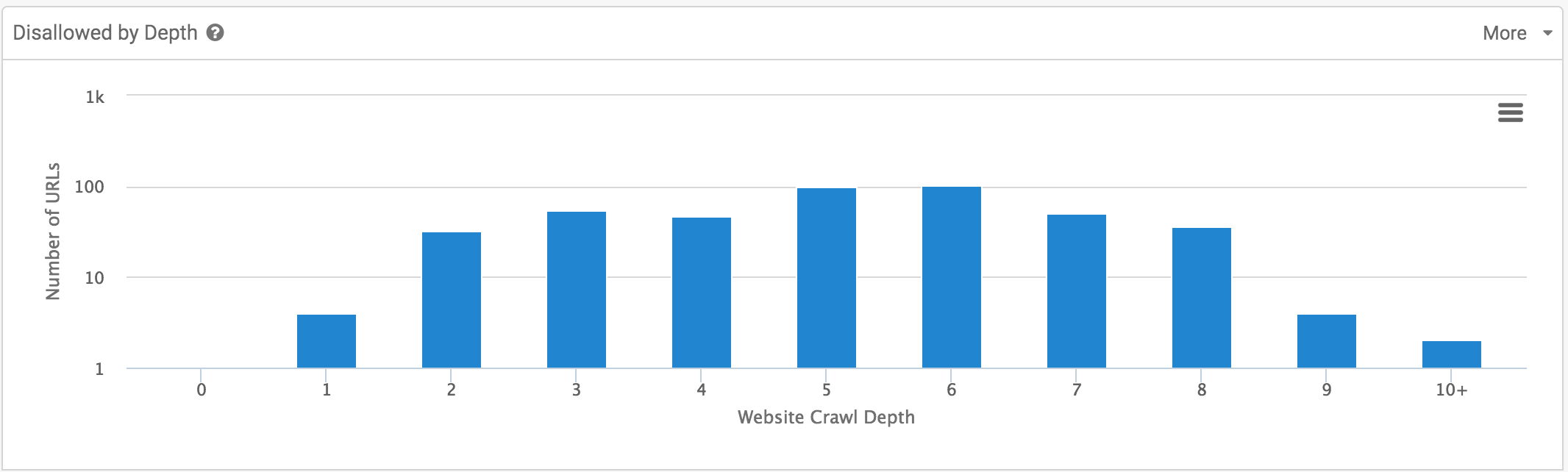
- Canonicalization by depth

También podemos observar la indexación por nivel de profundidad del rastreo, quizás sería interesante también tenerlo por tipo de contenido

Como en el resto de secciones, tenemos los Hints agrupados en este caso por Robots y por Canonical, donde se ve que no hay discrepancias ni errores actualmente.
Salvo algunas páginas que están recibiendo enlaces follow y no follow, algo que es contradictorio para las señales que le indicamos a Google, que podremos analizar más a fondo pulsando en View
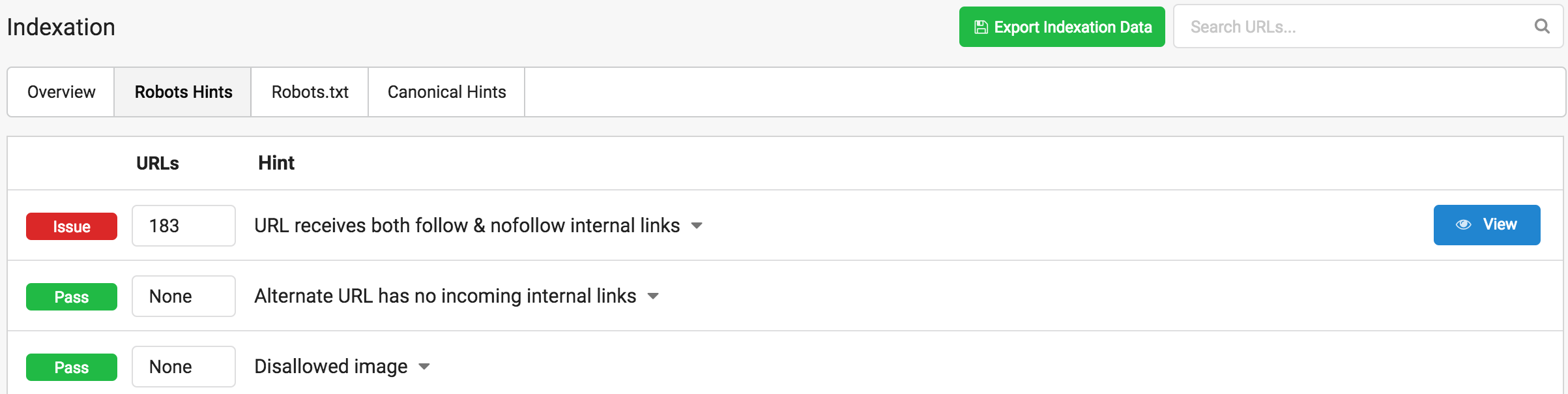
Nos mostrará la tabla de los 183 casos en los que se enlazan con follow y nofollow internamente, y esto me viene perfecto para mostrar otra funcionalidad más concreta, pulsando a nivel de url, nos habilita la información individual de esa url.

Como veis en este ejemplo, el contenido ha sido encontrado por el crawler gracias a la paginación, un punto interesante a tener en cuenta para un blog, donde los contenidos van quedándose lejos o profundos, respecto a la home.
Las pestañas que se ven arriba del todo de la imagen, son las que nos van a permitir saber desde qué lugares nos han enlazado con nofollow y sin él.

En este caso, los nofollow están ubicados en los links de «responder» en la zona de comentarios, que se montan con un parámetro ?repyto y un #respond.

On Page
El módulo on page está centrado en contenidos, el análisis de legibilidad y sentimiento de los mismos, y por otro lado, en la parte más de relevancia y visibilidad, es decir, lo que tiene que ver con titles y description y su status.
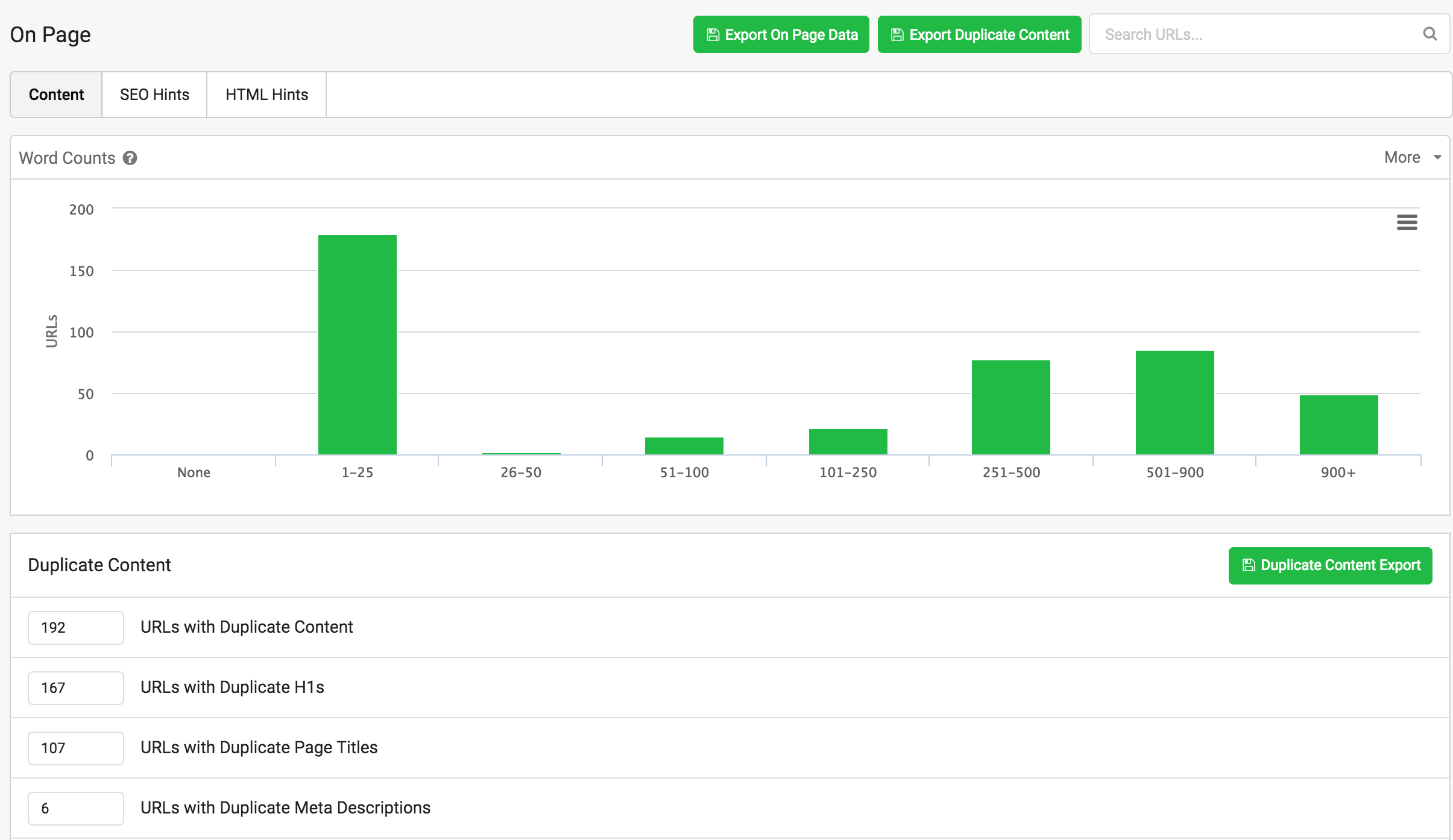
Este primer overview de Word Count nos indica el volumen de urls que tienen entre 1 y 25 palabras, entre 26-50, etc.
Con este gráfico, de un vistazo, observamos la extensión de contenidos del proyecto, dependiendo de la web que analicéis y su naturaleza de contenidos, pues los tramos serán más o menos relevantes.
Proyectos de contenidos, quizás tendrán los últimos tramos con mayor concentración de urls, sin embargo si pensamos en webs de clasificados, con textos cortos en los listados, quizás estén más concentrados en los tramos del centro.
También de un solo vistazo podemos ver el diagnóstico general en lo que a etiquetas se refiere, si tenemos duplicados o no.
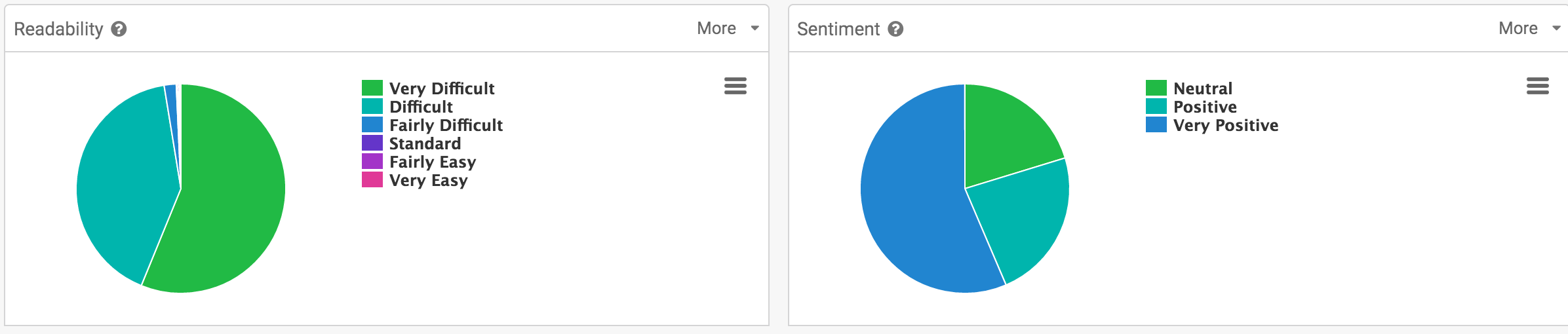
Profundizando más en la legibilidad , nos indica el grado de dificultad del texto, basándose en el mismo test que usa Yoast. Para el lado de sentimiento, se basa en AFINN-111, clasifica las palabras de un texto contra el index de palabras en inglés del lexicon, para determinar el tono o sentimiento, entre -5 y 5, de muy negativo a muy positivo, pasando por negativo, neutral y positivo.
Peeeeeero lamentablemente solo aplica a inglés todavía, así que esperemos que en próximas versiones, pueda tener aplicación para el mercado e idioma hispano.
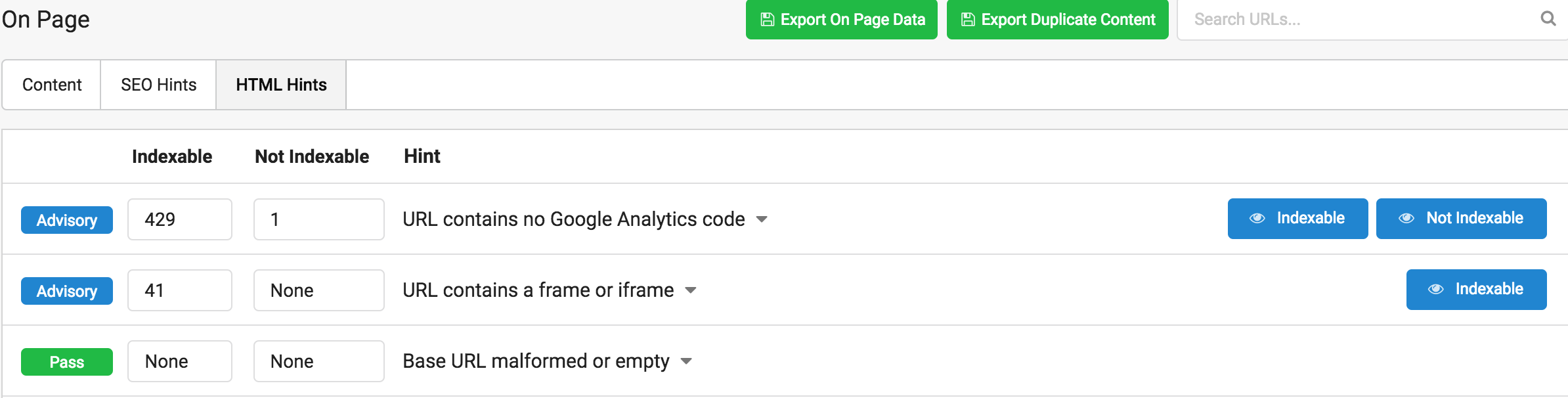
Como a lo largo de toda la herramienta, siempre tenemos la sección Hints, para tener quick wins o atajos para resolver lo más prioritario, como por ejemplo, alertas sobre el código de Analytics o urls en iframes.
Muy TOP que divida los hints ente urls Indexables y No Indexables, para priorizar los cambios en las landings de valor SEO
Site Speed
Otra de las joyas de la corona es el informe de rendimiento o performance. Ya con ver todo rojo, me queda muy clara cuál es la asignatura pendiente de mi humilde web.
A pesar de obtener score digno de Speed, el resto de métricas dan un poco de miedo, pero hay que fijarse que son los peores datos de todo el crawleo.
El gráfico de TTFB y de Download Time, ya te dan el agregado y en los tramos, sigue habiendo drama pero hay un pequeño remanso de esperanza, con ciertos contenidos que si se descargan de forma veloz.


El gráfico por profundidad de niveles, también es una gran bofetada de realidad y mal rendimiento, por lo que a grandes rasgos, solo podemos mejorar y la siguiente vez que crawleemos el proyecto, comparar las mejoras.

Los hints a nivel de urls, concreta recomendaciones en masa y nos permite ver qué páginas tienen cada problemática. Por ejemplo muchas peticiones de CSS o JS, cosa a revisar por afectar a 177 urls.

A nivel de recursos, pues tenemos aspectos más globales de compresión u optimización generales.
Search Traffic
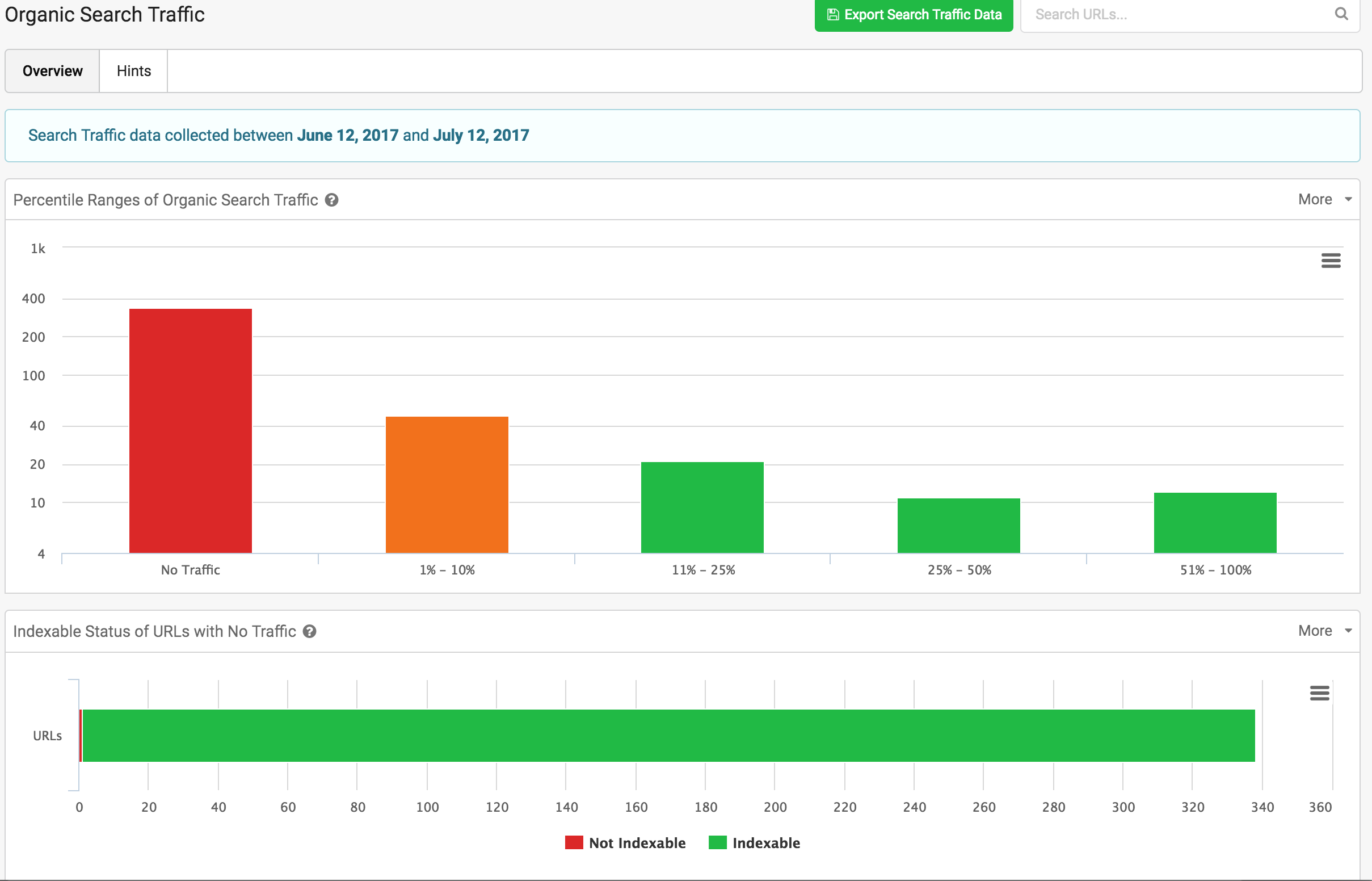
Otro valor diferencial respecto a otras tools, es que podemos sacar el bisturí y detectar de forma muy rápida las páginas que no están recibiendo tráfico orgánico en la franja elegida al conectar GSC o GA.
Se observa un volumen alto de urls que no generan ningún tráfico, concentrándose la mayoría de tráfico en pocas urls, cosa que en muchos proyectos, puede ser normal.
Es muy útil el gráfico de abajo, para saber si no tenemos tráfico por cuestiones de tener urls no indexables. Como se ve en este caso, no es así, ya que los contenidos están indexados, pero por el motivo que sea, no reciben tráfico:
- Contenidos antiguos u obsoletos que no hemos reciclado, optimizado ni borrado.
- Contenidos no optimizados o no orientados a sus topic objetivo
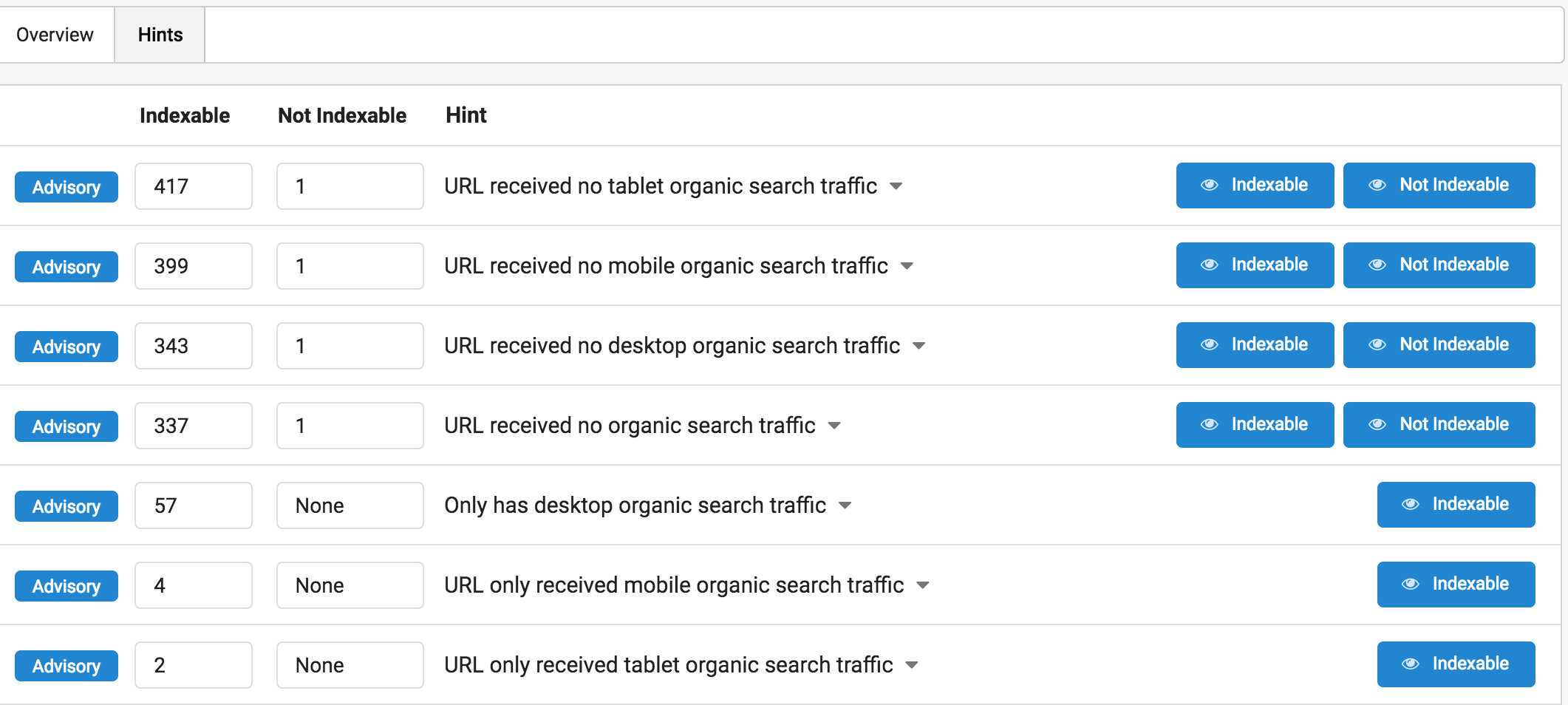
En esta sección, los Hints son especialmente interesantes, sobre todo porque te distingue entre mobile, desktop y tablet, lo cuál mola bastante para orientar correctamente a los distintos dispositivos, en base a nuestra audiencia y objetivo.
(A ponerse las pilas antes de que llegue el mobile first index, que luego a saber 😀 )
Sitemap
Esta opción también la echaba de menos en otras herramientas y es que nos hemos hinchado a cruzar urls del sitemap con urls indexadas y tráfico, para analizar qué estaba pasando con la indexación y la visibilidad final de las páginas top.
En esta sección por tanto podemos observar que no están agregadas todas las urls indexables al sitemap, principalmente solo se han añadido las del sitemap «page», por lo que los post del blog (la mayoría de urls de este site), no están añadidas.
El paso de .es a .com, nos ha trastocado las mentes y no hemos actualizado ni el robots.txt, ¡así somos!
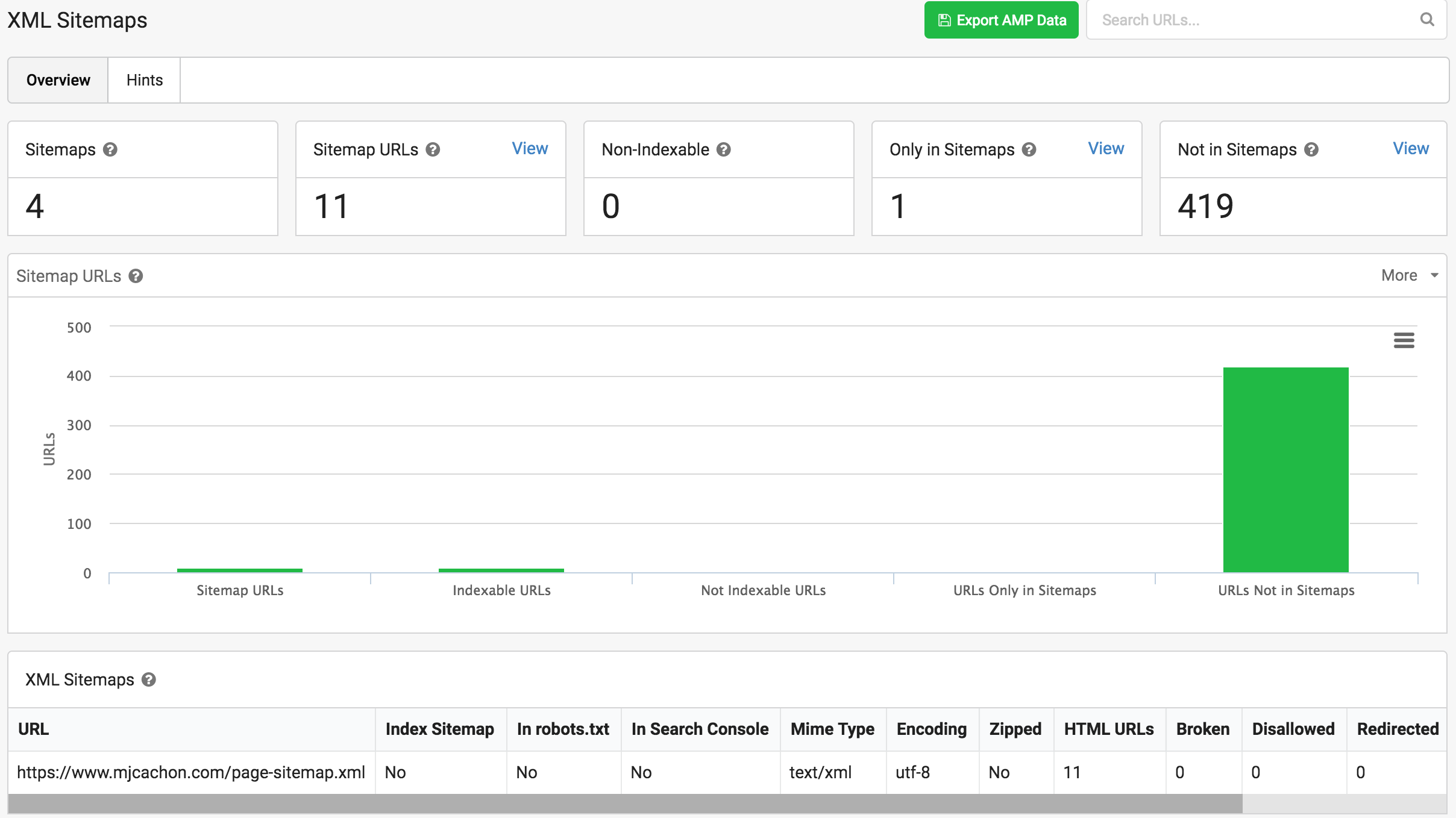
Si vemos el resto de opciones del panel, nos indica el status de los sitemaps, si tienen o no errores, y la info que cruza con GSC, todo en la misma pantalla, facilita bastante, la verdad 🙂

Lo dicho, no hemos enlazado los sitemaps bien en robots.txt y el sitemap de post, tiene errores en su construcción, la mejora más fácil de implementar, ¡gracias Sitebulb!
External
Llegando al final 😀
Los enlaces y recursos externos, nos lo resume en el típico gráfico de niveles de profundidad, para saber dónde hay más contenidos redirigidos o rotos, externos al proyecto analizado.
En mi caso, sigo arrastrando urls de mi dominio antiguo, así que muchos de los 892 redirects, son de mi enlazado interno sin optimizar (otra colleja para mi), en otros casos, se observa que muchos de los sites enlazados en los últimos años, desaparecieron o han pasado a https, es curioso 😀

En cualquier caso, salvo los casos que vienen de mi propio dominio .es, estos los voy a poner en el último lugar de la lista, hasta que no arregle el resto de cosas que estoy sacando de esta audit.
All Hints
Después de repasar todas las secciones de la herramienta, si quisiéramos ir directamente al grano, a las recomendaciones y sugerencias que nos da Sitebulb, podemos acceder al listado completo de Hints, separados por secciones.
Como veis, es una forma rápida y ágil de ir atajando problemáticas SEO.

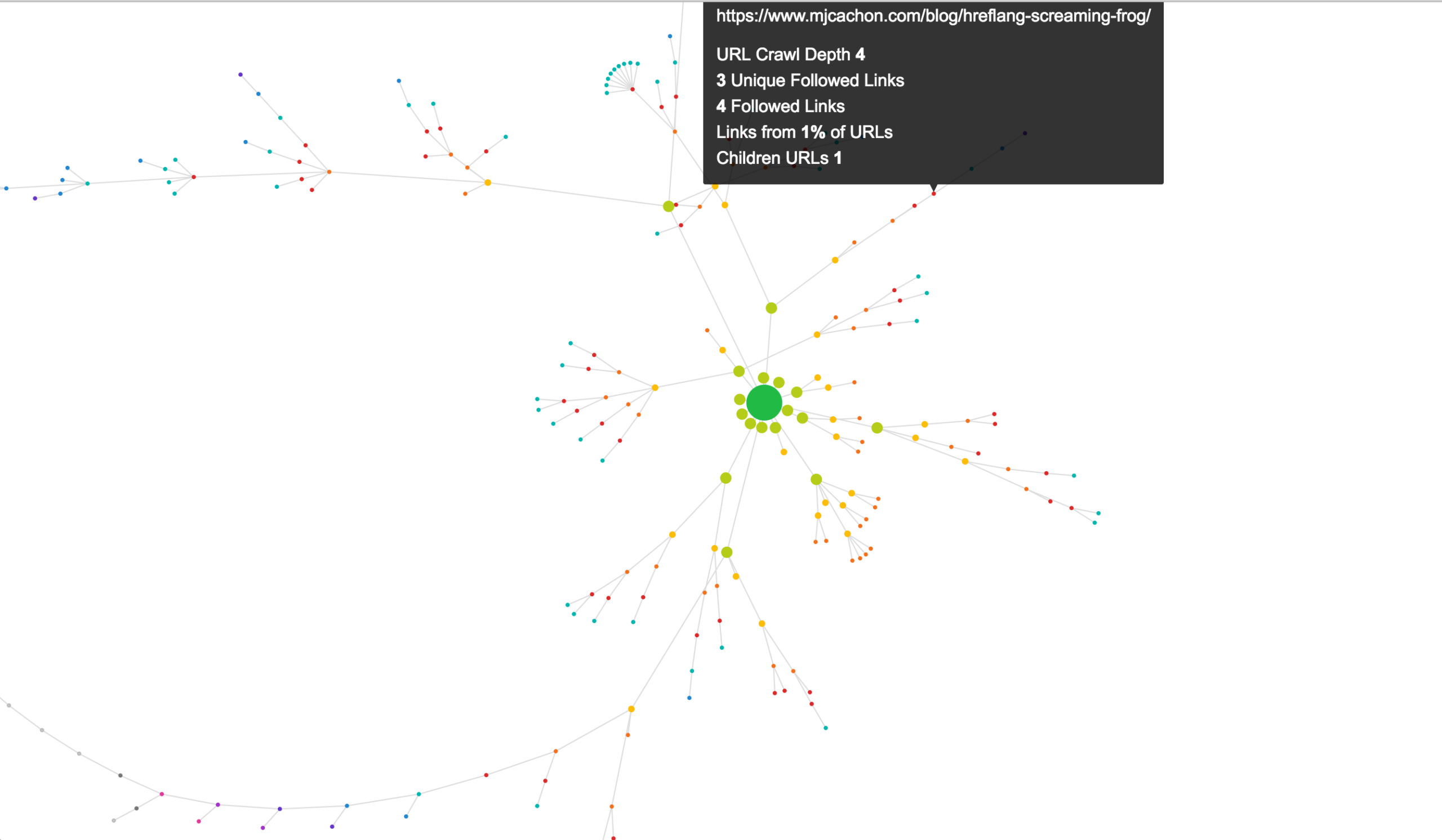
Crawl Map
Y para el final dejamos el mapa de rastreo que hace, con todos los nodos representados visualmente, y si nos posamos encima de alguno, nos da info de profundidad, enlaces internos recibidos y las urls que continúan descendiendo en la jerarquía.
El gráfico se puede ampliar o alejar e incluso, puedes ir moviendo los nodos y el resto de nodos acompañan y amoldan su posición.
No hay forma de descargar o no la he visto al menos, pero puede ser interesante para representar el rastreo de ciertas zonas de un site y justificar mejoras de enlazado interno 🙂

Otras funcionalidades interesantes para usar Sitebulb
- Gráficos clicables, que filtran la información
- Informes específicos por sección
- Hints por sección
- Buscador libre
- Descargas del crawleo

- Filtros en las tablas de datos
- Cambiar el orden por columnas, en las tablas de datos
![]()
Pues con todo esto, podemos dar por MUY BUENA y digna, esta primera versión de Sitebulb, y eso que aún nos quedaría un segundo post para analizar la parte Mobile, AMP e Internacional.
¡Espero que este tocho os sea de utilidad!



Espectacular post MJ. Le voy a dar una lectura más sosegada y práctica este fin de semana, porque lo merece, sin ninguna duda. Gracias por mostrarnos una herramienta con tan buena pinta.
Todavía está en beta pero pinta muy bien, al menos para sitios pequeños y medianos, con los grandes aún no sé si puede 🙂
Me falta revisar la parte de render mobile, internacional, amp y ver cómo se sacan los reports Sample, pero vaya, sino sería ya un post muy largo 😀
Buenas MJ,
Muchas gracias por el post.
La verdad es que estoy deseando utilizar la herramienta,
¿Sabes cuando estará disponible?
Muchas gracias de nuevo!
Hola!
Se supone que durante verano, pero puedes preguntar directamente en twitter, responden muy gustosamente 🙂
https://twitter.com/sitebulb
Gracias por comentar!
Hola MJ
Gracias por la review, habrá que probarlo. Al final la mejor manera de conocer la potencia de uno de cada uno de estos crawlers es lanzarlo sobre un sitio para el que ya conoces sus fortalezas y debilidades.
Por cierto, no tiene nada dedicado al contenido dupicado?
Un saludo y gracias de nuevo
Hola Javier, si que tiene una zona de contenido duplicado donde te informa de que URLs están compartiendo contenido idéntico. Un saludo.
No conocía este crawler, que bueno que dan 14 días para probarlo a ver que tal está. Me gusta bastante el tema de gráficos que tiene.
Muy interesante y completo. Habrá que aprender, gracias