
Si no habéis utilizado mucho Screaming Frog, no habréis reparado en funcionalidades más que interesantes que esta herramienta ofrece.
Para que no sea un post exageradamente largo, vamos a ir al grano, enumerando y explicando como exprimir un poco más este magnífico software.
1. Rastrear y analizar un sitio en entorno de pruebas
Si tenemos un sitio en pruebas, o un entorno de pre-producción donde comprobar cambios antes de que estén online, podemos chequear con Screaming Frog, esa web.
A priori, si solo se trata de un permiso por IP, la herramienta rastreará normalmente, siempre que la hagas funcionar bajo esa IP.
Ahora, esos entornos, por cuestiones de seguridad, suelen estar protegidos bajo usuario y contraseña, por lo que solo tendremos que hacer lo siguiente:
- Desde el menú de Screaming Frog, elegir «Configuración» – «Spider»
- Pinchar en la pestaña «Avanzado»
- Marcar la opción «request authentication»
- Y una vez tengamos ya configurado el restro de opciones para nuestro analisis o crawling, añadir la url y darle a «Start»
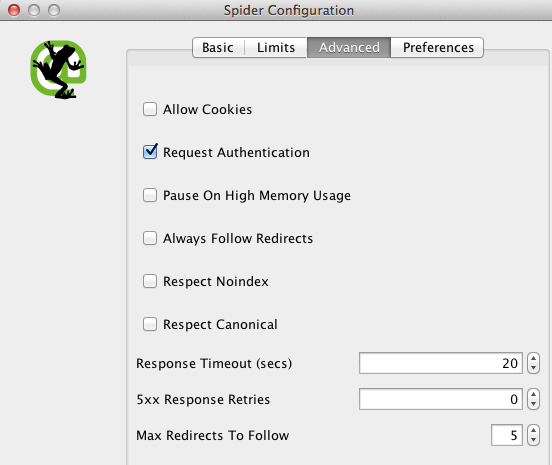
Y una vez empiece Screaming a carburar, nos saldrá una ventana para introducir usuario y contraseña que nos permita hacer efectivo el rastreo.
Recuerda que en ocasiones estos sitios de pruebas o de pre-producción, están bloqueados por robots.txt, así que es probable que haya que usar el «ignore robots.txt» que viene en la pestaña «Basic»
2. Conocer el tráfico orgánico que reciben tus urls accesibles
Podemos usar una reciente actualización de Screaming para conocer de un solo vistazo, qué tráfico orgánico (o del canal que queramos) tienen las urls que son potencialmente rastreables e indexables.
Simulamos un rastreo con el user agent de Googlebot y conectamos a la api de Google Analytics para que nos de los datos de tráfico de canales, fechas y métricas que queramos:
- Configuración >> User Agent >> Googlebot Regular
- Configuración >> Spider >> Advanced >> Respect Noindex y Respect Canonical
- Configuración >> Api Access >> Google Analytics
El punto 3, precisa que vinculemos nuestra cuenta de Google Analytics, autorizando a Screaming Frog expresamente.
Una vez hecho, al conectar, nos da a elegir Vista y luego ya toda la parte de datos, métricas y rangos de fecha
El rastreo se efectuará al tiempo que se hacen llamadas a la api de Analytics para recabar los datos solicitados, combinados con los datos del rastreo de Screaming.
¿Qué hacemos con esto, os preguntaréis?
- Tenemos las urls a las que google es susceptible de llegar
- Tenemos elementos de optimización (etiquetas, enlaces internos…)
- Tenemos datos de tráfico orgánico que reciben en un periodo dado
- Y también tenemos cuáles NO han recibido ni una mísera visita.
Pues se me ocurren varias ideas, ya que el análisis solo está hecho para urls de un blog:
- Las que han tenido mucho tráfico, pueden darte pistas como temas sobre los que escribir más frecuentemente
- Las que tienen un tráfico medio, quizás puedas revisar cómo optimizarlas
- Las que no reciben nada de tráfico, obviamente hay que diferenciar si son contenidos asociados a temporalidad (eventos o cosas que hayan quedado obsoletas)
En cualquier caso, tenemos en el panel derecho, una opción llamada «Overview» y si llegamos a la opción de Analytics, mi rastreo ha concluido con un 37% de urls sin datos de tráfico, por lo que debería empezar a analizar esas urls antes que ningunas.
Al hilo de esto, también existe una opción de Report llamado GA Not Matched, que te ofrece lo opuesto a No GA Data, es decir, te da una lista de urls que Google Analytics si reporta con tráfico, pero que el crawler no ha sido capaz de llegar a ellas.
¿Por qué puede ocurrir esto?
Pues hay varias opciones:
- Páginas huérfanas a las que el crawler no llega
- Páginas que se han podido quedar «colgadas» de una migración.
- Páginas que ya no existen pero que han tenido tráfico en algún momento del rango seleccionado
En mi ejemplo, existe un listado de urls antiguas, ya que hicimos cambios para poner el directorio /blog/ delante de los slud de los artículos, el crawleo ya no llega a esas urls, pero siguen registrando algún tráfico.
3. Vista en modo Arbol
Usando el ejemplo anterior con Analytics, para que se vea mucho mejor, tenemos una opción que a veces pasa muy desapercibida, y se trata de elegir el modo en que visualizamos los datos.
Por defecto tenemos la vista en modo List, pero podemos cambiarla a Tree, desde cualquier parte de Screaming, estemos viendo titles, directivas, o los datos de Analytics.
Una vez te lo agrupe en carpetas, puedes pulsar botón derecho sobre ellas y colapsarlas o expandirlas para agrupar la información, una funcionalidad muy útil que ya usaba DeepCrawl.
Recuerda, que cada vez que cambies de opción, por ejemplo, estando en Titles, te vas a Response Codes, te cambia la vista a List.

4. Opciones básicas de edición: mover, ordenar, borrar, copiar…
Detalles que también pueden pasar inadvertidos, ¿sabes que se pueden mover las columnas y poner el orden que queramos? ¿O que puedes ordenar los datos por la columna que quieras?
Para mover columnas:
- Drag and drop, simplemente pulsando y arrastrando la columna que quieras mover
- Soltar donde la quieras dejar, no nos acompaña haciendo scroll, así que paciencia 🙂
Mirad que orden de columnas he puesto, a modo de ejemplo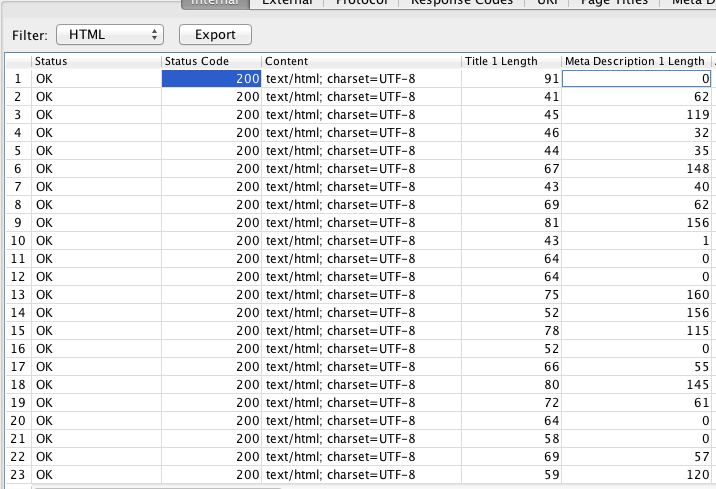
Para ordenar datos por una columna, esto es obvio:
- Pulsas sobre la cabecera de columna que quieres que actúe como criterio de ordenación
- Y ya.
Verás que está ordenado por esa columna porque tiene una flechita encima. Por ejemplo, ordeno por status code y tengo los errores arriba del todo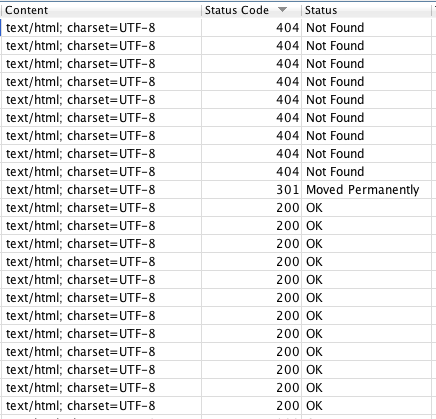
Ahora imagínate que has emulado a googlebot, y ya tienes controlados donde hay redirecciones y errores 4xx.
Podríamos borrar esas urls de screaming y la herramienta recalcularía todos los % de etiquetas, y datos que impliquen esas urls que eliminamos del panel. Como solo nos quedan las urls que dan 200 y son las rastreables e indexables, podríamos crear un sitemap sobre esas, presuponiendo que no lo tiene ya.
Con esto introduzco las opciones que nos ofrece si encima de una url pulsamos botón derecho:
Como veis, podríamos borrarla del panel, o hacer otras comprobaciones como visualizarla en navegador, exportar datos concretos de esa url, chequear con herramientas externas, sus backlinks, caché, etc.
¿Útil eh?
5. Visualizar el snippet para una url
Te pones encima de una url, la que quieras, y puede ver, con las etiquetas actuales que tiene, cómo se ve en un resultado de Google, tanto en desktop como en mobile
Con la tabla de datos de número de caracteres, pixeles y lo que te falta o sobra en cada caso.
Y si además, quieres emular cómo quedaría de otro modo, o con microformatos, pues visualizas y si te convence, pues ya te tocaría modificarlo en la web.

Al hilo de esto, puedes bajarte el report SERP Summary, que te descarga la lista de urls con los elementos necesarios para construir el snippet: title, description, url y sus correspondientes dimensiones.
Desde «Reports» >> SERP Summary, ya te dejarán elegir si quieres toda la información o solo la de elementos ausentes o duplicados
6. Extraer en un solo clic, los 404 de tu enlazado interno
Este export es muy útil y rápido de conseguir
Como sabéis, cuanto más limpio esté el enlazado interno, mejor que mejor, así que a pulir los 30x y los 40x, para que la navegación del usuario sea lo más satisfactoria posible y los rastreos de google, también.
7. Limitar los parámetros o la longitud de las urls
En la configuración de Screaming, existe una opción de «Limits», que podemos utilizar de formas muy interesantes.
A veces los crawleos de determinados sitios se pueden eternizar y no acabar nunca, y realmente no necesitamos crawlear al detalle cientos de miles de urls.
Las opciones de esta pestaña, nos ayudarán a restringir el crawleo a los parámetros que elijamos, para los dos casos que comento, sería «tunear» las dos que aparecen marcadas en la foto.
En una ocasión, «la rana» se encontraba enlaces relativos, y se fue haciendo un lío cada url que rastreaba, pues iba concatenando con el enlace relativo y al final se convertían en urls enormes, que no tenían fin.
La opción de limitar longitud, me hubiera ahorrado bastante quebradero de cabeza 🙂
8. Probar robots.txt
Y además de usar GSC como probador de robots.txt, también se puede usar Screaming, en modo lista, aprovechando de su configuración > Spider > «Show internal URLs blocked by robots.txt».
Una vez subamos urls que puedan o no, estar bloqueadas en robots, en modo lista, tendremos el resultado habitual, y luego desde Response Codes, la linea exacta que bloquea la url
Y por hoy, suficiente, si se os ocurren otros usos o trucos de Screaming Frog, comentad, malditos 🙂
Otras ideas para hacer en Screaming Frog:
Rastrear sitios grandes con Screaming FrogComprobar ortografía y gramática con Screaming Frog
Usar el inspector de Google Search Console en bulk con Screaming Frog
Auditar hreflang con Screaming Frog
Usar el probador de robots.txt de Screaming Frog



{kind=link}
Normalmente uso Xenu para analizar urls, pero parece que habrá que acabar usando Screaming Frog, tiene muchas más utilidades.
Gracias por el articulo.
Un saludo,
Mario
Buenas tardes, muchas gracias por la información es una herramienta increíble.
Gracias a tu recomendación he averiguado que tengo muchas URL bloqueadas por por robots.txt
¿Como podría quitarlo? Es una plantilla per-diseñada y me imagino que se deberá a eso.
¡Muchas gracias de ante mano!
Muy buen aporte, llevo horas buscando como limitar los saltos que tiene que hacer la rana, o sea que si encuentra un link solo craulee un salto para que no se haga una tarea interminable.